Creating a Locale
There are several ways to create a Locale object. Regardless of the technique used, creation can be as simple as specifying the language code. However, you can further distinguish the locale by setting the region (also referred to as "country") and variant codes. If you are using the JDK 7 release or later, you can also specify the script code and Unicode locale extensions.
The four ways to create a Locale object are:
Version Note:
The Locale.Builder class and the forLanguageTag method were added in the Java SE 7 release.
LocaleBuilder Class
The
Locale.Builder utility class can be used to construct a Locale object that conforms to the IETF BCP 47 syntax. For example, to specify the French language and the country of Canada, you could invoke the Locale.Builder constructor and then chain the setter methods as follows:
Locale aLocale = new Locale.Builder().
setLanguage("fr").setRegion("CA").build();
The next example creates Locale objects for the English language in the United States and Great Britain:
Locale bLocale = new Locale.Builder().
setLanguage("en").setRegion("US").build();
Locale cLocale = new Locale.Builder().
setLanguage("en").setRegion("GB").build();
The final example creates a Locale object for the Russian language:
Locale dLocale = new Locale.Builder().
setLanguage("ru").setScript("Cyrl").build();
Locale Constructors
There are three constructors available in the Locale class for creating a Locale object:
-
Locale(String language) -
Locale(String language, String country) -
Locale(String language, String country, String variant)
The following examples create Locale objects for the French language in Canada, the English language in the U.S. and Great Britain, and the Russian language.
aLocale = new Locale("fr", "CA");
bLocale = new Locale("en", "US");
cLocale = new Locale("en", "GB");
dLocale = new Locale("ru");
It is not possible to set a script code on a Locale object in a release earlier than JDK 7.
forLanguageTag Factory Method
If you have a language tag string that conforms to the IETF BCP 47 standard, you can use the
forLanguageTag(String) factory method, which was introduced in the Java SE 7 release. For example:
Locale aLocale = Locale.forLanguageTag("en-US");
Locale bLocale = Locale.forLanguageTag("ja-JP-u-ca-japanese");
Locale Constants
For your convenience the Locale class provides
constants for some languages and countries. For example:
cLocale = Locale.JAPAN; dLocale = Locale.CANADA_FRENCH;
When you specify a language constant, the region portion of the Locale is undefined. The next three statements create equivalent Locale objects:
j1Locale = Locale.JAPANESE;
j2Locale = new Locale.Builder().setLanguage("ja").build();
j3Locale = new Locale("ja");
The Locale objects created by the following three statements are also equivalent:
j4Locale = Locale.JAPAN;
j5Locale = new Locale.Builder().
setLanguage("ja").setRegion("JP").build();
j6Locale = new Locale("ja", "JP");
Codes
The following sections discuss the language code and the optional script, region, and variant codes.
Language Code
The language code is either two or three lowercase letters that conform to the ISO 639 standard. You can find a full list of the ISO 639 codes at http://www.loc.gov/standards/iso639-2/php/code_list.php.
The following table lists a few of the language codes.
| Language Code | Description |
|---|---|
de |
German |
en |
English |
fr |
French |
ru |
Russian |
ja |
Japanese |
jv |
Javanese |
ko |
Korean |
zh |
Chinese |
Script Code
The script code begins with an uppercase letter followed by three lowercase letters and conforms to the ISO 15924 standard. You can find a full list of the ISO 15924 codes at http://unicode.org/iso15924/iso15924-codes.html.
The following table lists a few of the script codes.
| Script Code | Description |
|---|---|
Arab |
Arabic |
Cyrl |
Cyrillic |
Kana |
Katakana |
Latn |
Latin |
There are three methods for retrieving the script information for a Locale:
-
getScript()– returns the 4-letter script code for aLocaleobject. If no script is defined for the locale, an empty string is returned. -
getDisplayScript()– returns a name for the locale's script that is appropriate for display to the user. If possible, the name will be localized for the default locale. So, for example, if the script code is "Latn," the diplay script name returned would be the string "Latin" for an English language locale. -
getDisplayScript(Locale)– returns the display name of the specifiedLocalelocalized, if possible, for the locale.
Region Code
The region (country) code consists of either two or three uppercase letters that conform to the ISO 3166 standard, or three numbers that conform to the UN M.49 standard. A copy of the codes can be found at http://www.chemie.fu-berlin.de/diverse/doc/ISO_3166.html.
The following table contains several sample country and region codes.
| A-2 Code | A-3 Code | Numeric Code | Description |
|---|---|---|---|
AU |
AUS |
036 |
Australia |
BR |
BRA |
076 |
Brazil |
CA |
CAN |
124 |
Canada |
CN |
CHN |
156 |
China |
DE |
DEU |
276 |
Germany |
FR |
FRA |
250 |
France |
IN |
IND |
356 |
India |
RU |
RUS |
643 |
Russian Federation |
US |
USA |
840 |
United States |
Variant Code
The optional variant code can be used to further distinguish your Locale. For example, the variant code can be used to indicate dialectical differences that are not covered by the region code.
Version Note:
Prior to the Java SE 7 release, the variant code was sometimes used to identify differences that were not specific to the language or region. For example, it might have been used to identify differences between computing platforms, such as Windows or UNIX. Under the IETF BCP 47 standard, this use is discouraged.
To define non-language-specific variations relevant to your environment, use the extensions mechanism, as explained in BCP 47 Extensions.
As of the Java SE 7 release, which conforms to the IETF BCP 47 standard, the variant code is used specifically to indicate additional variations that define a language or its dialects. The IETF BCP 47 standard imposes syntactic restrictions on the variant subtag. You can see a list of variant codes (search for variant) at http://www.iana.org/assignments/language-subtag-registry.
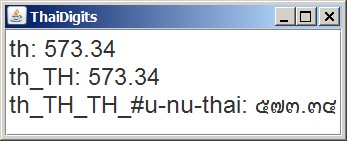
For example, Java SE uses the variant code to support the Thai language. By convention, a NumberFormat object for the th and th_TH locales will use common Arabic digit shapes, or Arabic numerals, to format Thai numbers. However, a NumberFormat for the th_TH_TH locale uses Thai digit shapes. The excerpt from
ThaiDigits.java demonstrates this:
String outputString = new String();
Locale[] thaiLocale = {
new Locale("th"),
new Locale("th", "TH"),
new Locale("th", "TH", "TH")};
for (Locale locale : thaiLocale) {
NumberFormat nf =
NumberFormat.getNumberInstance(locale);
outputString = outputString +
locale.toString() + ": ";
outputString = outputString +
nf.format(573.34) + "\n";
}
The following is a screenshot of this sample: