



ASA SQL User's Guide
Designing Your Database
The design process
To identify the required data
Identify supporting data.
List all the data you need to track.
Set up data for each entity.
List the available data for each entity. The data that describes an entity (subject) answers the questions who, what, where, when, and why.
List any data required for each relationship (verb).
List the data, if any, that applies to each relationship.
The supporting data you identify will become the names of the attributes of the entity. For example, the data below might apply to the Employee entity, the Skill entity, and the Expert In relationship.
| Employee | Skill | Expert In |
|---|---|---|
| Employee ID | Skill ID | Skill level |
| Employee first name | Skill name | Date skill was acquired |
| Employee last name | Description of skill | |
| Employee department | ||
| Employee office | ||
| Employee address |
If you make a diagram of this data, it will look something like this picture:
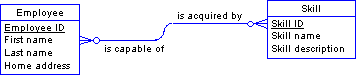
Observe that not all of the attributes you listed appear in this diagram. The missing items fall into two categories:
Some are contained implicitly in other relationships; for example, Employee department and Employee office are denoted by the relations to the Department and Office entities, respectively.
Others are not present because they are associated not with either of these entities, but rather the relationship between them. The above diagram is inadequate.
The first category of items will fall naturally into place when you draw the entire entity-relationship diagram.
You can add the second category by converting this many-to-many relationship into an entity.

The new entity depends on both the Employee and the Skill entities. It borrows its identifiers from these entities because it depends on both of them.
When you are identifying the supporting data, be sure to refer to the activities you identified earlier to see how you will access the data.
For example, you may need to list employees by first name in some situations and by last name in others. To accommodate this requirement, create a First Name attribute and a Last Name attribute, rather than a single attribute that contains both names. With the names separate, you can later create two indexes, one suited to each task.
Choose consistent names. Consistency makes it easier to maintain your database and easier to read reports and output windows.
For example, if you choose to use an abbreviated name such as Emp_status for one attribute, you should not use a full name, such as Employee_ID, for another attribute. Instead, the names should be Emp_status and Emp_ID.
At this stage, it is not crucial that the data be associated with the correct entity. You can use your intuition. In the next section, you'll apply tests to check your judgment.