



ASA SQL User's Guide
Designing Your Database
The design process
Normalization is a series of tests that eliminate redundancy in the data and make sure the data is associated with the correct entity or relationship. There are five tests. This section presents the first three of them. These three tests are the most important and so the most frequently used.
Why normalize?The goals of normalization are to remove redundancy and to improve consistency. For example, if you store a customer's address in multiple locations, it is difficult to update all copies correctly when they move. |
For more information about the normalization tests, see a book on database design.
There are several tests for data normalization. When your data passes the first test, it is considered to be in first normal form. When it passes the second test, it is in second normal form, and when it passes the third test, it is in third normal form.
To normalize data in a database
List the data.
Identify at least one key for each entity. Each entity must have an identifier.
Identify keys for relationships. The keys for a relationship are the keys from the two entities that it joins.
Check for calculated data in your supporting data list. Calculated data is not normally stored in a relational database.
Put data in first normal form.
If an attribute can have several different values for the same entry, remove these repeated values.
Create one or more entities or relationships with the data that you remove.
Put data in second normal form.
Identify entities and relationships with more than one key.
Remove data that depends on only one part of the key.
Create one or more entities and relationships with the data that you remove.
Put data in third normal form.
Remove data that depends on other data in the entity or relationship, not on the key.
Create one or more entities and relationships with the data that you remove.
Before you begin to normalize (test your design), simply list the data and identify a unique identifier each table. The identifier can be made up of one piece of data (attribute) or several (a compound identifier).
The identifier is the set of attributes that uniquely identifies each row in an entity. For example, the identifier for the Employee entity is the Employee ID attribute. The identifier for the Works In relationship consists of the Office Code and Employee ID attributes.
You can make an identifier for each relationship in your database by taking the identifiers from each of the entities that it connects. In the following table, the attributes identified with an asterisk are the identifiers for the entity or relationship.
| Entity or Relationship | Attributes |
|---|---|
| Office |
*Office code
Office address Phone number |
| Works in |
*Office code
*Employee ID |
| Department |
*Department ID
Department name |
| Heads |
*Department ID
*Employee ID |
| Member of |
*Department ID
*Employee ID |
| Skill |
*Skill ID
Skill name Skill description |
| Expert in |
*Skill ID
*Employee ID Skill level Date acquired |
| Employee |
*Employee ID
last name first name Social security number Address phone number date of birth |
To test for first normal form, look for attributes that can have repeating values.
Remove attributes when multiple values can apply to a single item. Move these repeating attributes to a new entity.
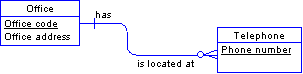
In the entity below, Phone number can repeat—an office can have more than one telephone number.

Remove the repeating attribute and make a new entity called Telephone. Set up a relationship between Office and Telephone.
Remove data that does not depend on the whole key.
Look only at entities and relationships whose identifier is composed of more than one attribute. To test for second normal form, remove any data that does not depend on the whole identifier. Each attribute should depend on all of the attributes that comprise the identifier.
In this example, the identifier of the Employee and Department entity is composed of two attributes. Some of the data does not depend on both identifier attributes; for example, the department name depends on only one of those attributes, Department ID, and Employee first name depends only on Employee ID.

Move the identifier Department ID, which the other employee data does not depend on, to a entity of its own called Department. Also move any attributes that depend on it. Create a relationship between Employee and Department.
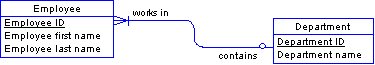
Remove data that doesn't depend directly on the key.
To test for third normal form, remove any attributes that depend on other attributes, rather than directly on the identifier.
In this example, the Employee and Office entity contains some attributes that depend on its identifier, Employee ID. However, attributes such as Office location and Office phone depend on another attribute, Office code. They do not depend directly on the identifier, Employee ID.

Remove Office code and those attributes that depend on it. Make another entity called Office. Then, create a relationship that connects Employee with Office.
