![]()
![]()
Chapter 2 Programming Information
This section discusses database issues relevant to jConnect and includes these topics:
jConnect versions 4.5 and 5.5 support the failover feature available in Adaptive Server Enterprise version 12.0 and later.
![]() Sybase failover in a high availability system is a different
feature than "connection failover." Sybase strongly
recommends that you read this section very carefully
if
you want to use both.
Sybase failover in a high availability system is a different
feature than "connection failover." Sybase strongly
recommends that you read this section very carefully
if
you want to use both.
Sybase failover allows you to configure two version 12.0 or later Adaptive Servers as companions. If the primary companion fails, that server's devices, databases, and connections can be taken over by the secondary companion.
You can configure a high availability system either asymmetrically or symmetrically.
An asymmetric configuration includes two Adaptive Servers, each physically located on a different machine, that are connected so that if one of the servers is brought down, the other assumes its workload. The secondary Adaptive Server acts as a "hot standby" and does not perform any work until failover occurs.A symmetric configuration also includes two Adaptive Servers running on separate machines. However, if failover occurs, either Adaptive Server can act as a primary or secondary companion for the other Adaptive Server. In this configuration, each Adaptive Server is fully functional with its own system devices, system databases, user databases, and user logins.In either setup, the two machines are configured for dual access, which makes the disks visible and accessible to both machines.You can enable failover in jConnect and connect a client application to an Adaptive Server configured for failover. If the primary server fails over to the secondary server, the client application also automatically switches to the second server and reestablishes network connections.
![]() Refer to Using Sybase Failover in High Availability
Systems for more detailed information.
Refer to Using Sybase Failover in High Availability
Systems for more detailed information.
To implement failover support in jConnect:
dn: servername=haprimary, o=Sybase, c=US 1.3.6.1.4.1.897.4.2.5: TCP#1#hostname 4200 1.3.6.1.4.1.897.4.2.15: servername=hasecondary objectclass: sybaseServer
dn: servername=hasecondary, o=Sybase, c=US 1.3.6.1.4.1.897.4.2.5: TCP#1#hostname 4202 objectclass: sybaseServer
dn: servername=haprimary, o=Sybase, c=US 1.3.6.1.4.1.897.4.2.5: TCP#1#hostname 4200 1.3.6.1.4.1.897.4.2.15: servername=hasecondary, o=Sybase, c=US ou=Accounting objectclass: sybaseServer
dn: servername=hasecondary, o=Sybase, c=US, ou=Accounting 1.3.6.1.4.1.897.4.2.5: TCP#1#hostname 4202 objectclass: sybaseServer
hasecondary
is
located in a different branch of the tree (see the additional ou=Accounting
qualifier).
dn: servername=hafailover, o=Sybase, c=US 1.3.6.1.4.1.897.4.2.5: TCP#1#hostname 4200 1.3.6.1.4.1.897.4.2.15: ldap://ldapserver: 386/servername=secondary, o=Sybase, c=US ou=Accounting objectclass: sybaseServer
dn: servername=secondary, o=Sybase, c=US, ou=Accounting 1.3.6.1.4.1.897.4.2.5: TCP#1#hostname 4202 objectclass: sybaseServer
dn: servername=SYBASE11,o=MyCompany,c=US 1.3.6.1.4.1.897.4.2.5:TCP#1#tahiti 3456 1.3.6.1.4.1.897.4.2.10:REPEAT_READ=false&PACKETSIZE=1024 1.3.6.1.4.1.897.4.2.10:CONNECTION_FAILOVER=false 1.3.6.1.4.1.897.4.2.11:pubs2 1.3.6.1.4.1.897.4.2.9:Tds 1.3.6.1.4.1.897.4.2.15:servername=SECONDARY 1.3.6.1.4.1.897.4.2.10:REQUEST_HA_SESSION=true
dn:servername=SECONDARY, o=MyCompany, c=US
1.3.6.1.4.1.897.4.2.5:TCP#1#moorea 6000
/* get the connection */
Connection con = DriverManager.getConnection
("jdbc:sybase:jndi:ldap://ldap_server1:983" +
"/servername=Sybase11,o=MyCompany,c=US",props);
or
props.put(Context.PROVIDER_URL, "ldap://ldap_server1:983/ o=MyCompany, c=US");
Connection con=DriverManager.getConnection
("jdbc:sybase:jndi:servername=Sybase11", props);
If an Adaptive Server is not configured for failover, or for some reason cannot grant a failover session, the client cannot log in, and the following warning displays:
'The server denied your request to use the high-availability feature. Please reconfigure your database, or do not request a high-availability session.'
When failover occurs, the SQL exception JZ0F2 is thrown:
'Sybase high-availability failover has occurred. The current transaction is aborted, but the connection is still usable. Retry your transaction.'
The client then automatically reconnects to the secondary database using JNDI.
Note that:
At some point, the client will fail back from the secondary server to the primary server. When failback occurs is determined by the System Administrator who issues sp_failback on the secondary server. Afterward, the client can expect the same behavior and results on the primary server as documented in "Failing over to the secondary server".
A Transact-SQL language command or stored procedure running on one server can execute a stored procedure located on another server. The server to which an application has connected logs in to the remote server, and executes a server-to-server remote procedure call.
An application can specify a "universal" password for server-to-server communication; that is, a password used in all server-to-server connections. Once the connection is open, the server uses this password to log in to any remote server.
By default, jConnect uses the current connection's password as the default password for server-to-server communications.
However, if the passwords are different on two servers for the same user and that user is performing server-to-server remote procedure calls, the application must explicitly define passwords for each server it plans to use.
jConnect versions 4.1 and later include a property that lets you set a universal "remote" password or different passwords on several servers. jConnect lets you set and configure the property using the setRemotePassword( ) method in the SybDriver class:
Properties connectionProps = new Properties(); public final void setRemotePassword(String serverName, String password, Properties connectionProps)
To use this method, the application needs to import the SybDriver class, then call the method.
For jConnect 4.x:
import com.sybase.jdbcx.SybDriver;
SybDriver sybDriver = (SybDriver)
Class.forName("com.sybase.jdbc.SybDriver").newInstance();
sybDriver.setRemotePassword
(serverName, password, connectionProps);
For jConnect 5.x:
import com.sybase.jdbcx.SybDriver;
SybDriver sybDriver = (SybDriver)
Class.forName("com.sybase.jdbc2.jdbc.SybDriver").newInstance();
sybDriver.setRemotePassword
(serverName, password, connectionProps);
![]() To set different remote passwords for various servers,
repeat the preceding call (appropriate for your version of jConnect)
for each server.
To set different remote passwords for various servers,
repeat the preceding call (appropriate for your version of jConnect)
for each server.
This call adds the given server name-password pair to the given Properties object, which can be passed by the application to DriverManager in DriverManager.getConnection (server_url, props).
If serverName is NULL, the universal password will be set to password for subsequent connections to all servers except the ones specifically defined by previous calls to setRemotePassword( ).
When an application sets the REMOTEPWD property, jConnect no longer sets the default universal password.
Adaptive Server Enterprise version 12.5 and later offer larger limits on the number of columns and parameters you can use. For example:
To take advantage of this capability, jConnect version 4.5 and 5.5 users need to set their JCONNECT_VERSION property to VERSION_6 or VERSION_LATEST. This will request that the server enable wide table support.
![]() jConnect continues to work with an Adaptive Server version
12.5 and later if you set the version to below VERSION_6.
However, if you try selecting from a table that requires wide table
support to fully retrieve the data, you may encounter unexpected
errors or data truncation. You can also set the version to VERSION_6 or VERSION_LATEST
when you access data from a Sybase server that does not support
wide tables. In this case, the server simply ignores your request
for wide table support.
jConnect continues to work with an Adaptive Server version
12.5 and later if you set the version to below VERSION_6.
However, if you try selecting from a table that requires wide table
support to fully retrieve the data, you may encounter unexpected
errors or data truncation. You can also set the version to VERSION_6 or VERSION_LATEST
when you access data from a Sybase server that does not support
wide tables. In this case, the server simply ignores your request
for wide table support.
Wide table support offers an extra benefit for jConnect users, besides the larger number of columns and parameters--a greater amount of ResultSetMetaData. For example, in versions of jConnect earlier than 4.5 and 5.5, the ResultSetMetaData methods getCatalogName, getSchemaName, and getTableName all returned "Not Implemented" SQLExceptions because that metadata was not supplied by the server. When you enable wide table support, the server now sends back this information, and the three methods return useful information.
To support JDBC DatabaseMetaData methods, Sybase provides a set of stored procedures that jConnect can call for metadata about a database. These stored procedures must be installed on the server for the JDBC metadata methods to work.
If the stored procedures for providing metadata are not already installed in a Sybase server, you can install them using stored procedure scripts provided with jConnect:
![]() The most recent version of these scripts is compatible
with all versions of jConnect.
The most recent version of these scripts is compatible
with all versions of jConnect.
See the Sybase jConnect for JDBC Installation Guide and Release Bulletin for complete instructions on installing stored procedures.
In addition, to use the metadata methods, you must set the USE_METADATA connection property to true (its default value) when you establish a connection.
You cannot get metadata about temporary tables in a database.
![]() The DatabaseMetaData.getPrimaryKeys( ) method
finds primary keys declared in a table definition (CREATE TABLE)
or with alter table (ALTER TABLE ADD CONSTRAINT). It does not find
keys defined using sp_primarykey.
The DatabaseMetaData.getPrimaryKeys( ) method
finds primary keys declared in a table definition (CREATE TABLE)
or with alter table (ALTER TABLE ADD CONSTRAINT). It does not find
keys defined using sp_primarykey.
Metadata support can be implemented in either the client (ODBC, JDBC) or in the data source (server stored procedures). jConnect provides metadata support on the server, which results in the following benefits:
jConnect 5.x implements many JDBC 2.0 cursor and update methods. These methods make it easier to use cursors and to update rows in a table based on values in a result set.
![]() To have full JDBC 2.0 support, use jConnect version
5.x or later. jConnect version 4.x provides some JDBC 2.0 features
via Sybase extensions and the ScrollableResultSet.java sample
found in the sample subdirectory under your
jConnect directory. See the com.sybase.jdbcx and
the sample packages for the javadocs on these
methods.
To have full JDBC 2.0 support, use jConnect version
5.x or later. jConnect version 4.x provides some JDBC 2.0 features
via Sybase extensions and the ScrollableResultSet.java sample
found in the sample subdirectory under your
jConnect directory. See the com.sybase.jdbcx and
the sample packages for the javadocs on these
methods.
In JDBC 2.0, ResultSets are characterized by their type and their concurrency. The type and concurrency values are part of the java.sql.ResultSet interface and are described in its javadocs.
Table 2-5 identifies the characteristics of java.sql.ResultSet that are available in jConnect 5.x.
| Concurrency | Type | ||
|---|---|---|---|
| TYPE_FORWARD_ ONLY |
TYPE_SCROLL_ INSENSITIVE |
TYPE_SCROLL_ SENSITIVE |
|
| CONCUR_READ_ONLY | Supported in 5.x | Supported in 5.x | Not available in 5.x |
| CONCUR_UPDATABLE | Supported in 5.x | Not available in 5.x | Not available in 5.x |
This section includes the following topics:
To create a cursor using jConnect 4.x, use either SybStatement.setCursorName( ) or SybStatement.setFetchSize( ). When you use SybStatement.setCursorName( ), you explicitly assign the cursor a name. The signature for SybStatement.setCursorName( ) is:
void setCursorName(String name) throws SQLException;
You use SybStatement.setFetchSize( ) to create a cursor and specify the number of rows returned from the database in each fetch. The signature for SybStatement.setFetchSize( ) is:
void setFetchSize(int rows) throws SQLException;
When you use setFetchSize( ) to create a cursor, the jConnect driver names the cursor. To get the cursor's name, use ResultSet.getCursorName( ).
You create cursors in jConnect version 5.x the same way as in version 4.x, but because version 5.x supports JDBC 2.0, there is another way to create cursors. You can specify which kind of ResultSet you want returned by the statement, using the following JDBC 2.0 method on the connection:
Statement createStatement(int resultSetType, int resultSetConcurrency)throws SQL Exception
The type and concurrency correspond to the types and concurrences found on the ResultSet interface listed in Table 2-5. If you request an unsupported ResultSet, a SQL warning is chained to the connection. When the returned Statement is executed, you will receive the kind of ResultSet that is most like the one you requested. See the JDBC 2.0 specification for more details on this method's behavior.
If you do not use createStatement( ), or you are using jConnect version 4.x, the default types of ResultSet are:
To verify that the kind of ResultSet object is what you intended, the JDBC 2.0 API for ResultSet has added two methods:
int getConcurrency() throws SQLException;
int getType() throws SQLException;
The basic steps for creating and using a cursor are:
// With conn as a Connection object, create a
// Statement object and assign it a cursor using
// Statement.setCursorName().
Statement stmt = conn.createStatement();
stmt.setCursorName("author_cursor");
// Use the statement to execute a query and return
// a cursor result set.
ResultSet rs = stmt.executeQuery("SELECT au_id,
au_lname, au_fname FROM authors
WHERE city = 'Oakland'");
while(rs.next())
{
...
}
// Create a second statement object and use
// SybStatement.setFetchSize()to create a cursor
// that returns 10 rows at a time.
SybStatement syb_stmt = conn.createStatement();
syb_stmt.setFetchSize(10);
// Use the syb_stmt to execute a query and return
// a cursor result set.
SybCursorResultSet rs2 =
(SybCursorResultSet)syb_stmt.executeQuery
("SELECT au_id, au_lname, au_fname FROM authors
WHERE city = 'Pinole'");
while(rs2.next())
{
...
}
// Get the name of the cursor created through the
// setFetchSize() method.
String cursor_name = rs2.getCursorName();
...
// For jConnect 5.x, create a third statement // object using the new method on Connection, // and obtain a SCROLL_INSENSITIVE ResultSet. // Note: you no longer have to downcast the // Statement or the ResultSet.
Statement stmt = conn.createStatement( ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_READ_ONLY);
ResultSet rs3 = stmt.executeQuery
("SELECT ... [whatever]");
// Execute any of the JDBC 2.0 methods that // are valid for read only ResultSets.
rs3.next(); rs3.previous(); rs3.relative(3); rs3.afterLast();
...
The following example shows how to use methods in JDBC 1.x to do a positioned update. The example creates two Statement objects, one for selecting rows into a cursor result set, and the other for updating the database from rows in the result set.
// Create two statement objects and create a cursor
// for the result set returned by the first
// statement, stmt1. Use stmt1 to execute a query
// and return a cursor result set.
Statement stmt1 = conn.createStatement();
Statement stmt2 = conn.createStatement();
stmt1.setCursorName("author_cursor");
ResultSet rs = stmt1.executeQuery("SELECT
au_id,au_lname, au_fname
FROM authors WHERE city = 'Oakland'
FOR UPDATE OF au_lname");
// Get the name of the cursor created for stmt1 so
// that it can be used with stmt2.
String cursor = rs.getCursorName();
// Use stmt2 to update the database from the
// result set returned by stmt1.
String last_name = new String("Smith");
while(rs.next())
{
if (rs.getString(1).equals("274-80-9391"))
{
stmt2.executeUpdate("UPDATE authors "+
"SET au_lname = "+last_name +
"WHERE CURRENT OF " + cursor);
}
}
The following example uses Statement object stmt2, from the preceding code, to perform a positioned deletion:
stmt2.executeUpdate("DELETE FROM authors
WHERE CURRENT OF " + cursor);
This section discusses JDBC 2.0 methods for updating columns in the current cursor row and updating the database from the current cursor row in a result set. They are followed by an example.
JDBC 2.0 specifies a number of methods for updating column values from a result set in memory, on the client. The updated values can then be used to perform an update, insert, or delete operation on the underlying database. All of these methods are implemented in the SybCursorResultSet class.
Examples of some of the JDBC 2.0 update methods available in jConnect are:
void updateAsciiStream(String columnName, java.io.InputStream x, int length) throws SQLException;
void updateBoolean(int columnIndex, boolean x) throws SQLException;
void updateFloat(int columnIndex, float x) throws SQLException;
void updateInt(String columnName, int x) throws SQLException;
void updateInt(int columnIndex, int x) throws SQLException;
void updateObject(String columnName, Object x) throws SQLException;
JDBC 2.0 specifies two new methods for updating or deleting rows in the database, based on the current values in a result set. These methods are simpler in form than Statement.executeUpdate( ) in JDBC 1.x and do not require a cursor name. They are implemented in SybCursorResultSet:
void updateRow() throws SQLException; void deleteRow() throws SQLException;
![]() The concurrency of the result set must be CONCUR_UPDATABLE, otherwise
the above methods will raise an exception. For insertRow(
), all table columns that require non-null entries must
be specified.
The concurrency of the result set must be CONCUR_UPDATABLE, otherwise
the above methods will raise an exception. For insertRow(
), all table columns that require non-null entries must
be specified.
Methods provided on DatabaseMetaData dictate
when these changes are visible.
The following example creates a single Statement object that is used to return a cursor result set. For each row in the result set, column values are updated in memory and then the database is updated with the row's new column values.
// Create a Statement object and set fetch size to
// 25. This creates a cursor for the Statement
// object Use the statement to return a cursor
// result set.
SybStatement syb_stmt =
(SybStatement)conn.createStatement();
syb_stmt.setFetchSize(25);
SybCursorResultSet syb_rs =
(SybCursorResultSet)syb_stmt.executeQuery(
"SELECT * from T1 WHERE ...")
// Update each row in the result set according to
// code in the following while loop. jConnect
// fetches 25 rows at a time, until fewer than 25
// rows are left. Its last fetch takes any
// remaining rows.
while(syb_rs.next())
{
// Update columns 2 and 3 of each row, where
// column 2 is a varchar in the database and
// column 3 is an integer.
syb_rs.updateString(2, "xyz");
syb_rs.updateInt(3,100);
//Now, update the row in the database.
syb_rs.updateRow();
}
// Create a Statement object using the // JDBC 2.0 method implemented in jConnect 5.x Statement stmt = conn.createStatement (ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_UPDATABLE);
// Use the Statement to return an updatable ResultSet
ResultSet rs = stmt.executeQuery("SELECT * FROM T1 WHERE...");
// In jConnect 5.x, downcasting to SybCursorResultSet is not
// necessary. Update each row in the ResultSet in the same
// manner as above
while (rs.next())
{
rs.updateString(2, "xyz");
rs.updateInt(3,100);
rs.updateRow();
}
To delete a row from a cursor result set, you can use SybCursorResultSet.deleteRow( ) as follows:
while(syb_rs.next())
{
int col3 = getInt(3);
if (col3 >100)
{
syb_rs.deleteRow();
}
}
The following example illustrates how to do inserts using the JDBC 2.0 API, which is only available in jConnect 5.x. There is no need to downcast to a SybCursorResultSet.
// prepare to insert rs.moveToInsertRow();
// populate new row with column values rs.updateString(1, "New entry for col 1"); rs.updateInt(2, 42);
// insert new row into db rs.insertRow();
// return to current row in result set rs.moveToCurrentRow();
Once you create a PreparedStatement object, you can use it multiple times with the same or different values for its input parameters. If you use a cursor with a PreparedStatement object, you need to close the cursor after each use and then reopen the cursor to use it again. A cursor is closed when you close its result set (ResultSet.close( )). It is opened when you execute its prepared statement (PreparedStatement.executeQuery( )).
The following example shows how to create a PreparedStatement object, assign it a cursor, and execute the PreparedStatement object twice, closing and then reopening the cursor.
// Create a prepared statement object with a
// parameterized query.
PreparedStatement prep_stmt =
conn.prepareStatement(
"SELECT au_id, au_lname, au_fname "+
"FROM authors WHERE city = ? "+
"FOR UPDATE OF au_lname");
//Create a cursor for the statement.
prep_stmt.setCursorName("author_cursor");
// Assign the parameter in the query a value.
// Execute the prepared statement to return a
// result set.
prep_stmt.setString(1, "Oakland");
ResultSet rs = prep_stmt.executeQuery();
//Do some processing on the result set.
while(rs.next())
{
...
}
// Close the result, which also closes the cursor.
rs.close();
// Execute the prepared statement again with a new
// parameter value. prep_stmt.setString(1,"San Francisco"); rs = prep_stmt.executeQuery();
// reopens cursor
jConnect version 5.x supports only TYPE_SCROLL_INSENSITIVE result sets.
jConnect uses the Tabular Data Stream (TDS)--Sybase's proprietary protocol--to communicate with Sybase database servers. As of jConnect 5.x, TDS does not support scrollable cursors. To support scrollable cursors, jConnect caches the row data on demand, on the client, on each call to ResultSet.next( ). However, when the end of the result set is reached, the entire result set is stored in the client's memory. Because this may cause a performance strain, we recommend that you use TYPE_SCROLL_INSENSITIVE result sets only when the result set is reasonably small.
![]() When you use TYPE_SCROLL_INSENSITIVE ResultSets in
jConnect 5.x, you can only call the isLast( ) method
after the last row of the ResultSet has been
read. Calling isLast( ) before the last row is
reached will cause an UnimplementedOperationException to
be thrown.
When you use TYPE_SCROLL_INSENSITIVE ResultSets in
jConnect 5.x, you can only call the isLast( ) method
after the last row of the ResultSet has been
read. Calling isLast( ) before the last row is
reached will cause an UnimplementedOperationException to
be thrown.
A sample has been added to jConnect version 4.x that provides a limited TYPE_SCROLL_INSENSITIVE ResultSet using JDBC 1.0 interfaces.
This implementation uses standard JDBC 1.0 methods to produce a scroll-insensitive, read-only result set; that is, a static view of the underlying data that is not sensitive to changes made while the result set is open. ExtendedResultSet caches all of the ResultSet rows on the client. Be cautious when you use this class with large result sets.
The sample.ScrollableResultSet interface:
The methods from the JDBC 2.0 API are:
boolean previous() throws SQLException;
boolean absolute(int row) throws SQLException; boolean relative(int rows) throws SQLException;
boolean first() throws SQLException; boolean last() throws SQLException; void beforeFirst() throws SQLException; void afterLast() throws SQLException;
boolean isFirst() throws SQLException; boolean isLast() throws SQLException; boolean isBeforeFirst() throws SQLException; boolean isAfterLast() throws SQLException;
int getFetchSize() throws SQLException; void setFetchSize(int rows) throws SQLException; int getFetchDirection() throws SQLException; void setFetchDirection(int direction) throws SQLException;
int getType() throws SQLException; int getConcurrency() throws SQLException; int getRow() throws SQLException;
To use the new sample classes, create an ExtendedResultSet using any JDBC 1.0 java.sql.ResultSet. Below are the relevant pieces of code (assume a Java 1.1 environment):
// import the sample files import sample.*;
//import the JDBC 1.0 classes import java.sql.*;
// connect to some db using some driver; // create a statement and a query;
// Get a reference to a JDBC 1.0 ResultSet ResultSet rs = stmt.executeQuery(_query);
// Create a ScrollableResultSet with it ScrollableResultSet srs = new ExtendedResultSet(rs);
// invoke methods from the JDBC 2.0 API srs.beforeFirst();
// or invoke methods from the JDBC 1.0 API if (srs.next()) String column1 = srs.getString(1);
Figure 2-1 is a class diagram that shows the relationships between the new sample classes and the JDBC API.
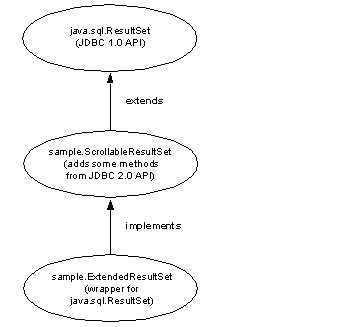
See the JDBC 2.0 API at http://java.sun.com/products/jdbc/jdbcse2.html for more details.
Batch updates allow a Statement object to submit multiple update commands as one unit (batch) to an underlying database for processing together.
![]() To use batch updates, you must refresh the SQL scripts
in the sp directory under your jConnect installation
directory.
To use batch updates, you must refresh the SQL scripts
in the sp directory under your jConnect installation
directory.
See BatchUpdates.java in the sample (jConnect 4.x) and sample2 (jConnect 5.x) subdirectories for an example of using batch updates with Statement, PreparedStatement, and CallableStatement.
jConnect also supports dynamic PreparedStatements in batch.
jConnect implements batch updates as specified in the JDBC 2.0 API, except as described below.
create proc sp_A as insert tableA values (1, 'hello A')
create proc sp_B as insert tableA values (1, 'hello A') update tableA set col1=2
create proc sp_C as update tableA set col1=2 delete tableA
0 Rows Affected 1 Rows Affected 2 Rows Affected
See Sun Microsystems, Inc. JDBC™ 2.0 API for more details on batch updates.
jConnect includes update and delete methods that allow you to get a cursor on the result set returned by a stored procedure. You can then use the cursor's position to update or delete rows in the underlying table that provided the result set. The methods are in SybCursorResultSet:
void updateRow(String tableName) throws SQLException;
void deleteRow(String tableName) throws SQLException;
The tableName parameter identifies the database table that provided the result set.
To get a cursor on the result set returned by a stored procedure, you need to use either SybCallableStatement.setCursorName( ) or SybCallableStatement.setFetchSize( ) before you execute the callable statement that contains the procedure. The following example shows how to create a cursor on the result set of a stored procedure, update values in the result set, and then update the underlying table using the SybCursorResultSet.update( ) method:
// Create a CallableStatement object for executing the stored
// procedure.
CallableStatement sproc_stmt =
conn.prepareCall("{call update_titles}");
// Set the number of rows to be returned from the database with
// each fetch. This creates a cursor on the result set.
(SybCallableStatement)sproc_stmt.setFetchSize(10);
//Execute the stored procedure and get a result set from it.
SybCursorResultSet sproc_result = (SybCursorResultSet)
sproc_stmt.executeQuery();
// Move through the result set row by row, updating values in the
// cursor's current row and updating the underlying titles table
// with the modified row values.
while(sproc_result.next())
{
sproc_result.updateString(...);
sproc_result.updateInt(...);
...
sproc_result.updateRow(titles);
}
jConnect has added the SybPreparedStatement extension to support the way Adaptive Server Enterprise handles the NUMERIC datatype where precision (total digits) and scale (digits after the decimal) can be specified.The corresponding datatype in Java--java.math.BigDecimal--is slightly different, and these differences can cause problems when jConnect applications use the setBigDecimal method to control values of an input/output parameter. Specifically, there are cases where the precision and scale of the parameter must precisely match that precision and scale of the corresponding SQL object, whether it is a stored procedure parameter or a column.To give jConnect applications fuller control over the setBigDecimal method, The SybPreparedStatement extension has been added with this method:
public void setBigDecimal (int parameterIndex, BigDecimal X, int scale, int precision) throws SQLException
See the SybPrepExtension.java sample in the /sample (jConnect 4.x) and /sample2 (jConnect 5.x) subdirectories under your jConnect installation directory for more information.
jConnect has a TextPointer class with sendData( ) methods for updating an image column in an Adaptive Server Enterprise or Adaptive Server Anywhere database. In earlier versions of jConnect, you had to send image data using the setBinaryStream( ) method in java.sql.PreparedStatement. The TextPointer.sendData( ) methods use java.io.InputStream and greatly improve performance when you send image data to an Adaptive Server database.
| WARNING! | The TextPointer class has been deprecated; that is, it is no longer recommended and may cease to exist in a future version of Java. If your data server is Adaptive Server 12.5 or later or Adaptive Server Anywhere version 6.0 or later, use the standard JDBC form to send image data:
PreparedStatement.setBinaryStream(int paramIndex, InputStream image) | ||
To obtain instances of the TextPointer class, you can use either of two getTextPtr( ) methods in SybResultSet:
public TextPointer getTextPtr(String columnName)
public TextPointer getTextPtr(int columnIndex)
The com.sybase.jdbc package contains the TextPointer class. Its public method interface is:
public void sendData(InputStream is, boolean log) throws SQLException
public void sendData(InputStream is, int length, boolean log) throws SQLException
public void sendData(InputStream is, int offset, int length, boolean log) throws SQLException
public void sendData(byte[] byteInput, int offset, int length, boolean log) throws SQLEXception
sendData(InputStream is, boolean log) - Updates an image column with data in the specified input stream.
sendData(InputStream is, int length, boolean log) - updates an image column with data in the specified input stream. length is the number of bytes being sent.
sendData(InputStream is, int offset, int length, boolean log) - updates an image column with data in the specified input stream, starting at the byte offset given in the offset parameter and continuing for the number of bytes specified in the length parameter.
sendData(byte[ ] byteInput, int offset, int length, boolean log) - updates a column with image data contained in the byte array specified in the byteInput parameter. The update starts at the byte offset given in the offset parameter and continues for the number of bytes specified in the length parameter.
Each method has a log parameter. The log parameter specifies whether image data is to be fully logged in the database transaction log. If the log parameter is set to true, the entire binary image is written into the transaction log. If the log parameter is set to false, the update is logged, but the image itself is not included in the log.
![]() Updating an image column with TextPointer.sendData(
)
Updating an image column with TextPointer.sendData(
)
To update a column with image data:
The next two sections illustrate these steps with an example. In the example, image data from the file Anne_Ringer.gif is sent to update the pic column of the au_pix table in the pubs2 database. The update is for the row with author ID 899-46-2035.
text and image columns contain timestamp and page-location information that is separate from their text and image data. When data is selected from a text or image column, this extra information is "hidden" as part of the result set.
A TextPointer object for updating an image column requires this hidden information, but does not need the image portion of the column data. To get this information, you need to select the column into a ResultSet object and then use SybResultSet.getTextPtr( ) (see the example that follows the next paragraph). SybResultSet.getTextPtr( ) extracts text-pointer information, ignores image data, and creates a TextPointer object.
When a column contains a significant amount of image data, selecting the column for one or more rows and waiting to get all the data is likely to be inefficient, since the data is not used. You can shortcut this process by using the set textsize command to minimize the amount of data returned in a packet. The following code example for getting a TextPointer object includes the use of set textsize for this purpose.
/*
* Define a string for selecting pic column data for author ID
* 899-46-2035.
*/
String getColumnData = "select pic from au_pix where au_id = '899-46-2035'";
/*
* Use set textsize to return only a single byte of column data
* to a Statement object. The packet with the column data will
* contain the "hidden" information necessary for creating a
* TextPointer object.
*/
Statement stmt= connection.createStatement();
stmt.executeUpdate("set textsize 1");
/*
* Select the column data into a ResultSet object--cast the
* ResultSet to SybResultSet because the getTextPtr method is
* in SybResultSet, which extends ResultSet.
*/
SybResultSet rs = (SybResultSet)stmt.executeQuery(getColumnData);
/*
* Position the result set cursor on the returned column data
* and create the desired TextPointer object.
*/
rs.next();
TextPointer tp = rs.getTextPtr("pic");
/*
* Now, assuming we are only updating one row, and won't need
* the minimum textsize set for the next return from the server,
* we reset textsize to its default value.
*/
stmt.executeUpdate("set textsize 0");
The following code uses the TextPointer object from the preceding section to update the pic column with image data in the file Anne_Ringer.gif.
/*
*First, define an input stream for the file.
*/
FileInputStream in = new FileInputStream("Anne_Ringer.gif");
/*
* Prepare to send the input stream without logging the image data
* in the transaction log.
*/
boolean log = false;
/*
* Send the image data in Anne_Ringer.gif to update the pic
* column for author ID 899-46-2035.
*/
tp.sendData(in, log);
See the TextPointers.java sample in the sample (jConnect 4.x) and sample2 (jConnect 5.x) subdirectories under your jConnect installation directory for more information.
In earlier versions, jConnect used a TextPointer class with sendData( ) methods for updating a text column in an Adaptive Server Enterprise or Adaptive Server Anywhere database.
The TextPointer class has been deprecated; that is, it is no longer recommended and may cease to exist in a future version of Java.
If your data server is Adaptive Server 12.5 or later or Adaptive Server Anywhere version 6.0 or later, use the standard JDBC form to send text data:
PreparedStatement.setAsciiStream(int paramIndex,
InputStream text, int length)
or
PreparedStatement.setUnicodeStream(int paramIndex,
InputStream text, int length)
or
PreparedStatement.setCharacterStream(int paramIndex,
Reader reader, int length)
JDBC uses three temporal datatypes: Time, Date, and Timestamp. Adaptive Server uses only one temporal datatype, datetime, which is equivalent to the JDBC Timestamp datatype. The Adaptive Server datetime datatype supports second resolution to 1/300th of a second.
All three JDBC datatypes are treated as datetime datatypes on the server side. A JDBC Timestamp is essentially the same as a server datetime; therefore, no conversion is necessary. However, translating a JDBC Time or Date datatype to or from a server datetime datatype requires a conversion.
Do not use rs.getByte( ) on a char, univarchar, unichar, varchar, or text field unless the data is hex, octal, or decimal.
| Copyright © 2001 Sybase, Inc. All rights reserved. |
| |