





















|
| | |
Parser configurations built using the Xerces Native Interface
are made from a series of parser components. This document
details the XNI API for these components and how they are put
together to construct a parser configuration in the following
sections:
In addition, several examples
are included to show how to create some parser components and
configurations:
 |
All of the interfaces and classes defined in this document
reside in the org.apache.xerces.xni.parser package
but may use various interfaces and classes from the core XNI
package, org.apache.xerces.xni.
|
|
The source code for the samples in this document are included
in the downloaded packages for Xerces2.
|
|
| | |
Parser configurations are comprised of a number of parser
components that perform various tasks. For example, a parser
component may be responsible for the actual scanning of XML
documents to generate document "streaming" information
events; another component may manage commonly used symbols
within the parser configuration in order to improve
performance; and a third component may even manage the
resolution of external parsed entities and the transcoding
of these entities from various international encodings into
Unicode used
within the Java virtual machine. When these components are
assembled in a certain way, they constitute a single parser
configuration but they can also be used interchangeably with
other components that implement the appropriate interfaces.
Note:
Even though a parser is comprised of a number of components,
not all of these components are configurable. In
other words, some components depend on knowing the state of
certain features and properties of the parser configuration
while others can operate completely independent of the parser
configuration. However, when we use the term "component" when
talking about XNI, we are talking about a configurable
component within the parser configuration.
The following diagram shows an example of this collection of
parser components: (Please note that this is not the only
configuration of parser components.)
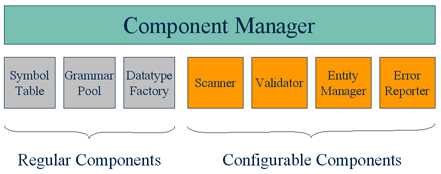
The only distinguishing feature of a component
is that it can be notified of the state
of parser features and properties. Features represent parser
state of type boolean whereas properties represent
parser state of type java.lang.Object. Each
component can also be queried for which features and properties
it recognizes.
| | |
This interface is the basic configurable component in a parser
configuration. It is managed by the
XMLComponentManager
which holds the parser state.
|
Components are managed by a component manager. The component
manager keeps track of the parser state for features and
properties. The component manager is responsible for notifying
each component when the value of those features and properties
change.
Before parsing a document, a parser configuration must
use the component manager to reset all of the parser components.
Then, during parsing, each time a feature or property value is
modified, all of the components must be informed of the
change.
Note:
A compliant XNI parser configuration is not
required to use any components that implement the
XMLComponent
interface. That interface is included as a convenience for
people building modular and configurable parser components.
The Xerces2 reference implementation uses the component
interface to implement its components so that they can be
used interchangeably in various configurations.
|
| | |
An XNI parser configuration defines the entry point for a
parser to set features and properties, initiate a parse of
an XML instance document, perform entity resolution, and
receive notification of errors that occurred in the document.
A parser configuration is typically comprised of a series of
parser components. Some of these components may be
connected together to form the parsing pipeline. This parser
configuration is then used by a specific parser implementation
that generates a particular API, such as DOM or SAX. The
separation between the parser configuration and parser instance
allows the same API-generating parser to be used with an
unlimited number of different parser configurations.
When a document is parsed, the parser configuration resets the
configurable components and initiates the scanning of the
document. Typically, a scanner starts scanning the document
which generates XNI information set events that are sent to
the next component in the pipeline (e.g. the validator). The
information set events coming out of the end of the pipeline
are then communicated to the document and DTD handlers that
are registered with the parser configuration.
The following diagram shows both the generic parsing pipeline
contained within a parser configuration and the separation of
parser configuration and specific parser classes.
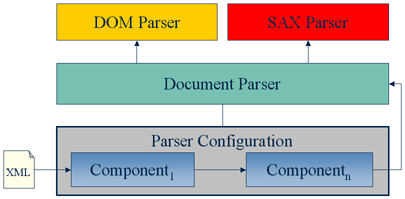
There are two parser configuration interfaces defined in XNI:
the XMLParserConfiguration and the
XMLPullParserConfiguration. For most purposes, the
standard parser configuration will suffice. Document and DTD
handler interfaces will be registered on the parser configuration
and the document will be parsed completely by calling the
parse(XMLInputSource) method. In this situation,
the application is driven by the output of the configuration.
However, the XMLPullParserConfiguration interface
extends the XMLParserConfiguration interface to
provide methods that allow the application to drive the
configuration. Any configuration class that implements this
interface guarantees that it can be driven in a pull parsing
fashion but does not make any statement as to how much or how
little pull parsing will be performed at each step.
| | |
This class represents an input source for an XML document. The
basic properties of an input source are the following:
public identifier,
system identifier,
byte stream or character stream.
|
| | |
A parsing exception. This exception is different from the standard
XNI exception in that it stores the location in the document (or
its entities) where the exception occurred.
|
|
| | |
The Core Interfaces provide
interfaces for the streaming information set. While these
interfaces are sufficient for communicating the document and
DTD information, it does not provide an easy way to construct
the pipeline or initiate the pipeline to start parsing an
XML document. The org.apache.xerces.xni.parser
package has additional interfaces to fill exactly this need.
Each parser configuration can be thought of as two separate
pipelines: one for document information and one for DTD
information. Each pipeline starts with a scanner and is followed
by zero or more filters (objects that implement interfaces
to handle the incoming information as well as register
handlers for the outgoing information). The information that
comes out the end of the pipeline is usually forwarded by
the parser configuration to the registered handlers.
There are two scanner interfaces defined: the XMLDocumentScanner
and the XMLDTDScanner:
| | |
This interface defines a DTD scanner. Typically, scanning of
the DTD internal subset is initiated from the XML document
scanner so the input source is implicitly the same as the
one used by the document scanner. Therefore, the
setInputSource method should only be called before
scanning of the DTD external subset.
|
Extends XMLDTDSource,
XMLDTDContentModelSource
|
| Methods
|
public void setInputSource(
XMLInputSource source
) throws java.io.IOException;
|
public boolean scanDTDInternalSubset(
boolean complete,
boolean standalone,
boolean hasExternalSubset
) throws java.io.IOException, XNIException;
|
public boolean scanDTDExternalSubset(
boolean complete
) throws java.io.IOException, XNIException;
|
|
Notice how each scanner interface's scanning methods take a
complete parameter and returns a boolean. This
allows (but does not require) scanners that implement these
interfaces to provide "pull" parsing behaviour in which the
application drives the parser's operation instead of having
parsing events "pushed" to the registered handlers.
After the scanners, zero or filters may be present in a parser
configuration pipeline. A document pipeline filter implements the
XMLDocumentHandler
interface from the XNI Core Interfaces as well as the
XMLDocumentSource
interface which allows filters to be chained together in
the pipeline. There are equivalents source interfaces for the
DTD information as well.
| | |
This interface allows a DTD handler to be registered.
|
| | |
Defines a DTD filter that acts as both a receiver and
an emitter of DTD events.
|
The next section gives some basic examples for using the XNI
framework to construct filters and parser configurations.
|
| | |
The following samples show how to create various parser components
and parser configurations. The XNI samples included with the Xerces2
reference release provide a convenient way to test a parser
configuration. For example, to test the
CSV Parser Configuration
example, run the following command:
 | | | | java xni.DocumentTracer -p CSVConfiguration document.csv | | | | |
Or a new CSV parser can be constructed that produces standard
SAX events. For example:
| | | | import org.apache.xerces.parsers.AbstractSAXParser;
public class CSVParser
extends AbstractSAXParser {
// Constructors
public CSVParser() {
super(new CSVConfiguration());
}
} // class CSVParser | | | | |
The following samples are available:
| | | | Abstract Parser Configuration | | | | |
| | |
This abstract parser configuration simply helps manage
components, features and properties, and other tasks common to
all parser configurations.
| | | | import java.io.FileInputStream;
import java.io.InputStream;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.Hashtable;
import java.util.Locale;
import java.util.Vector;
import org.apache.xerces.xni.XMLDocumentHandler;
import org.apache.xerces.xni.XMLDTDHandler;
import org.apache.xerces.xni.XMLDTDContentModelHandler;
import org.apache.xerces.xni.XNIException;
import org.apache.xerces.xni.parser.XMLComponent;
import org.apache.xerces.xni.parser.XMLConfigurationException;
import org.apache.xerces.xni.parser.XMLEntityResolver;
import org.apache.xerces.xni.parser.XMLErrorHandler;
import org.apache.xerces.xni.parser.XMLInputSource;
import org.apache.xerces.xni.parser.XMLParserConfiguration;
public abstract class AbstractConfiguration
implements XMLParserConfiguration {
// Data
protected final Vector fRecognizedFeatures = new Vector();
protected final Vector fRecognizedProperties = new Vector();
protected final Hashtable fFeatures = new Hashtable();
protected final Hashtable fProperties = new Hashtable();
protected XMLEntityResolver fEntityResolver;
protected XMLErrorHandler fErrorHandler;
protected XMLDocumentHandler fDocumentHandler;
protected XMLDTDHandler fDTDHandler;
protected XMLDTDContentModelHandler fDTDContentModelHandler;
protected Locale fLocale;
protected final Vector fComponents = new Vector();
// XMLParserConfiguration methods
public void addRecognizedFeatures(String[] featureIds) {
int length = featureIds != null ? featureIds.length : 0;
for (int i = 0; i < length; i++) {
String featureId = featureIds[i];
if (!fRecognizedFeatures.contains(featureId)) {
fRecognizedFeatures.addElement(featureId);
}
}
}
public void setFeature(String featureId, boolean state)
throws XMLConfigurationException {
if (!fRecognizedFeatures.contains(featureId)) {
short type = XMLConfigurationException.NOT_RECOGNIZED;
throw new XMLConfigurationException(type, featureId);
}
fFeatures.put(featureId, state ? Boolean.TRUE : Boolean.FALSE);
int length = fComponents.size();
for (int i = 0; i < length; i++) {
XMLComponent component = (XMLComponent)fComponents.elementAt(i);
component.setFeature(featureId, state);
}
}
public boolean getFeature(String featureId)
throws XMLConfigurationException {
if (!fRecognizedFeatures.contains(featureId)) {
short type = XMLConfigurationException.NOT_RECOGNIZED;
throw new XMLConfigurationException(type, featureId);
}
Boolean state = (Boolean)fFeatures.get(featureId);
return state != null ? state.booleanValue() : false;
}
public void addRecognizedProperties(String[] propertyIds) {
int length = propertyIds != null ? propertyIds.length : 0;
for (int i = 0; i < length; i++) {
String propertyId = propertyIds[i];
if (!fRecognizedProperties.contains(propertyId)) {
fRecognizedProperties.addElement(propertyId);
}
}
}
public void setProperty(String propertyId, Object value)
throws XMLConfigurationException {
if (!fRecognizedProperties.contains(propertyId)) {
short type = XMLConfigurationException.NOT_RECOGNIZED;
throw new XMLConfigurationException(type, propertyId);
}
if (value != null) {
fProperties.put(propertyId, value);
}
else {
fProperties.remove(propertyId);
}
int length = fComponents.size();
for (int i = 0; i < length; i++) {
XMLComponent component = (XMLComponent)fComponents.elementAt(i);
component.setProperty(propertyId, value);
}
}
public Object getProperty(String propertyId)
throws XMLConfigurationException {
if (!fRecognizedProperties.contains(propertyId)) {
short type = XMLConfigurationException.NOT_RECOGNIZED;
throw new XMLConfigurationException(type, propertyId);
}
Object value = fProperties.get(propertyId);
return value;
}
public void setEntityResolver(XMLEntityResolver resolver) {
fEntityResolver = resolver;
}
public XMLEntityResolver getEntityResolver() {
return fEntityResolver;
}
public void setErrorHandler(XMLErrorHandler handler) {
fErrorHandler = handler;
}
public XMLErrorHandler getErrorHandler() {
return fErrorHandler;
}
public void setDocumentHandler(XMLDocumentHandler handler) {
fDocumentHandler = handler;
}
public XMLDocumentHandler getDocumentHandler() {
return fDocumentHandler;
}
public void setDTDHandler(XMLDTDHandler handler) {
fDTDHandler = handler;
}
public XMLDTDHandler getDTDHandler() {
return fDTDHandler;
}
public void setDTDContentModelHandler(XMLDTDContentModelHandler handler) {
fDTDContentModelHandler = handler;
}
public XMLDTDContentModelHandler getDTDContentModelHandler() {
return fDTDContentModelHandler;
}
public abstract void parse(XMLInputSource inputSource)
throws IOException, XNIException;
public void setLocale(Locale locale) {
fLocale = locale;
}
// Protected methods
protected void addComponent(XMLComponent component) {
if (!fComponents.contains(component)) {
fComponents.addElement(component);
addRecognizedFeatures(component.getRecognizedFeatures());
addRecognizedProperties(component.getRecognizedProperties());
}
}
protected void resetComponents()
throws XMLConfigurationException {
int length = fComponents.size();
for (int i = 0; i < length; i++) {
XMLComponent component = (XMLComponent)fComponents.elementAt(i);
component.reset(this);
}
}
protected void openInputSourceStream(XMLInputSource source)
throws IOException {
if (source.getCharacterStream() != null) {
return;
}
InputStream stream = source.getByteStream();
if (stream == null) {
String systemId = source.getSystemId();
try {
URL url = new URL(systemId);
stream = url.openStream();
}
catch (MalformedURLException e) {
stream = new FileInputStream(systemId);
}
source.setByteStream(stream);
}
}
} // class AbstractConfiguration | | | | |
|
| | |
This example is a very simple parser configuration that can
parse files with comma-separated values (CSV) to generate
XML events. For example, the following CSV document:
| | | | Andy Clark,16 Jan 1973,Cincinnati | | | | |
produces the following XML "document" as represented by the
XNI streaming document information:
| | | | <?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE csv [
<!ELEMENT csv (row)*>
<!ELEMENT row (col)*>
<!ELEMENT col (#PCDATA)>
]>
<csv>
<row>
<col>Andy Clark</col>
<col>16 Jan 1973</col>
<col>Cincinnati</col>
</row>
</csv> | | | | |
Here is the source code for the CSV parser configuration.
Notice that it does not use any components. Rather, it implements
the CSV parsing directly in the parser configuration's
parse(XMLInputSource) method. This demonstrates
that you are not required to use the
XMLComponent interface but it is there for
building modular components that can be used in other
configurations.
| | | | import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.IOException;
import java.io.Reader;
import java.util.StringTokenizer;
import org.apache.xerces.util.XMLAttributesImpl;
import org.apache.xerces.util.XMLStringBuffer;
import org.apache.xerces.xni.QName;
import org.apache.xerces.xni.XMLAttributes;
import org.apache.xerces.xni.XMLDTDContentModelHandler;
import org.apache.xerces.xni.XNIException;
import org.apache.xerces.xni.parser.XMLInputSource;
public class CSVConfiguration
extends AbstractConfiguration {
// Constants
protected static final QName CSV = new QName(null, null, "csv", null);
protected static final QName ROW = new QName(null, null, "row", null);
protected static final QName COL = new QName(null, null, "col", null);
protected static final XMLAttributes EMPTY_ATTRS = new XMLAttributesImpl();
// Data
private final XMLStringBuffer fStringBuffer = new XMLStringBuffer();
// XMLParserConfiguration methods
public void setFeature(String featureId, boolean state) {}
public boolean getFeature(String featureId) { return false; }
public void setProperty(String propertyId, Object value) {}
public Object getProperty(String propertyId) { return null; }
public void parse(XMLInputSource source)
throws IOException, XNIException {
// get reader
openInputSourceStream(source);
Reader reader = source.getCharacterStream();
if (reader == null) {
InputStream stream = source.getByteStream();
reader = new InputStreamReader(stream);
}
BufferedReader bufferedReader = new BufferedReader(reader);
// start document
if (fDocumentHandler != null) {
fDocumentHandler.startDocument(null, "UTF-8");
fDocumentHandler.xmlDecl("1.0", "UTF-8", null);
fDocumentHandler.doctypeDecl("csv", null, null);
}
if (fDTDHandler != null) {
fDTDHandler.startDTD(null);
fDTDHandler.elementDecl("csv", "(row)*");
fDTDHandler.elementDecl("row", "(col)*");
fDTDHandler.elementDecl("col", "(#PCDATA)");
}
if (fDTDContentModelHandler != null) {
fDTDContentModelHandler.startContentModel("csv");
fDTDContentModelHandler.startGroup();
fDTDContentModelHandler.element("row");
fDTDContentModelHandler.endGroup();
short csvOccurs = XMLDTDContentModelHandler.OCCURS_ZERO_OR_MORE;
fDTDContentModelHandler.occurrence(csvOccurs);
fDTDContentModelHandler.endContentModel();
fDTDContentModelHandler.startContentModel("row");
fDTDContentModelHandler.startGroup();
fDTDContentModelHandler.element("col");
fDTDContentModelHandler.endGroup();
short rowOccurs = XMLDTDContentModelHandler.OCCURS_ZERO_OR_MORE;
fDTDContentModelHandler.occurrence(rowOccurs);
fDTDContentModelHandler.endContentModel();
fDTDContentModelHandler.startContentModel("col");
fDTDContentModelHandler.startGroup();
fDTDContentModelHandler.pcdata();
fDTDContentModelHandler.endGroup();
fDTDContentModelHandler.endContentModel();
}
if (fDTDHandler != null) {
fDTDHandler.endDTD();
}
if (fDocumentHandler != null) {
fDocumentHandler.startElement(CSV, EMPTY_ATTRS);
}
// read lines
String line;
while ((line = bufferedReader.readLine()) != null) {
if (fDocumentHandler != null) {
fDocumentHandler.startElement(ROW, EMPTY_ATTRS);
StringTokenizer tokenizer = new StringTokenizer(line, ",");
while (tokenizer.hasMoreTokens()) {
fDocumentHandler.startElement(COL, EMPTY_ATTRS);
String token = tokenizer.nextToken();
fStringBuffer.clear();
fStringBuffer.append(token);
fDocumentHandler.characters(fStringBuffer);
fDocumentHandler.endElement(COL);
}
fDocumentHandler.endElement(ROW);
}
}
bufferedReader.close();
// end document
if (fDocumentHandler != null) {
fDocumentHandler.endElement(CSV);
fDocumentHandler.endDocument();
}
}
} // class CSVConfiguration | | | | |
The source code is longer than it actually needs to be because
it also emits the DTD information necessary for a validating
parser to validate the document. The real core of the example
is the following:
| | | | fDocumentHandler.startDocument(null, "UTF-8");
fDocumentHandler.startElement(CSV, EMPTY_ATTRS);
String line;
while ((line = bufferedReader.readLine()) != null) {
if (fDocumentHandler != null) {
fDocumentHandler.startElement(ROW, EMPTY_ATTRS);
StringTokenizer tokenizer = new StringTokenizer(line, ",");
while (tokenizer.hasMoreTokens()) {
fDocumentHandler.startElement(COL, EMPTY_ATTRS);
String token = tokenizer.nextToken();
fStringBuffer.clear();
fStringBuffer.append(token);
fDocumentHandler.characters(fStringBuffer);
fDocumentHandler.endElement(COL);
}
fDocumentHandler.endElement(ROW);
}
}
fDocumentHandler.endElement(CSV);
fDocumentHandler.endDocument(); | | | | |
|
|
|
|