
|
|
|||||
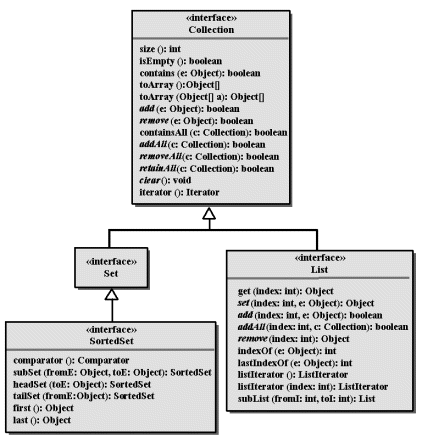
Collection: Collection bildet nur den kleinsten gemeinsamen Nenner aller Kollektionen und hat keine konkrete Implementierung. Nur für die abgeleiteten Interfaces existieren Klassen im Framework.
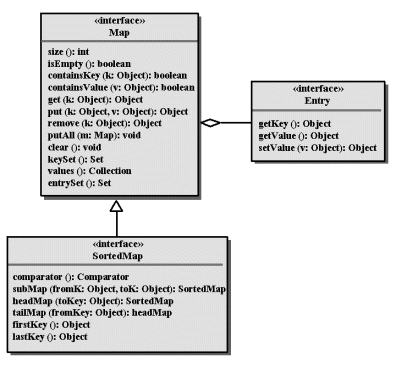
Map: Jeder Eintrag hat einen Schlüssel Die Map verbindet mit jedem Objekt ein eindeutiges Schlüssel-Objekt und hat somit eine Sonderstellung. Die Gemeinsamkeiten mit den anderen Aggregationen für eine gemeinsame Root erschienen zu gering (siehe Abb. 14.2).
Kollektionen sind aus Sicht ihrer Elemente generell, da sie beliebige Objekte als Elemente akzeptieren. MinimalismusWer andere Hierarchien vergleichbarer typisierter Sprachen wie C++ kennt, erkennt klare Unterschiede:
14.2.1 Unterstützende Interfaces
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
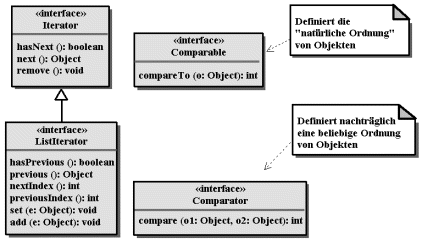
Die Iteratoren vereinfachen das Durchlaufen der Elemente in einer Kollektion und die beiden Compare-Interfaces erlauben eine generelle Art des Objektvergleichs.
Collection:
»abstrakte« Multimenge (Bag)
Eine Kollektion ist eine ungeordnete Ansammlung von Objekten, Elemente genannt.
| Eine Kollektion (Collection) enthält keine Einschränkungen bezüglich Typ, Anordnung oder Häufigkeit eines Elements. |
Mathematisch gesehen ist eine Kollektion eine Multimenge (Bag). Die Reihenfolge der Elemente ist ohne Bedeutung und nicht definiert.
| Eine Menge (Set) ist eine Kollektion, in der jedes Element höchstens einmal vorkommen kann. |
| Eine Liste (List) ist eine Kollektion, in der die Elemente angeordnet sind (z.B. in der Reihenfolge des Einfügens). Damit können die Elemente indiziert werden. |
Elementvergleich mit compare(), compareTo()
| Comparable bzw. Comparator vergleichen mit compareTo() bzw. compare() zwei Objekte auf kleiner, größer oder gleich. Sie liefern eine negative bzw. positive ganze Zahl, wenn das erste Objekt kleiner bzw. größer ist, oder Null, wenn die Objekte gleich sind.2 |
| Zur sortierten Menge (SortedSet) werden die Elemente anhand eines Sortierkriteriums, welches durch einen Comparator festgelegt wird. |
(List)Iteratoren durchlaufen Elemente
| Mit einem Iterator können alle Elemente in einer Kollektion genau einmal besucht werden, wobei die Reihenfolge nicht relevant ist. |
| Ein ListIterator durchläuft speziell Listen in der vorgegebenen Ordnung. |
Map:
Einträge als Schlüssel/Wert-Paare
Da Iteratoren einem gleichnamigen Pattern folgen, werden sie weiter unten in einem eigenen Abschnitt behandelt.
Logisch gesehen ist eine Map eine spezielle Kollektion.
| Bei einer Map besteht jedes Element Eintrag (Entry) genannt aus zwei assoziierten Werten, dem Schlüssel (Key), der eindeutig sein muss, und dem Wert (Value). |
Der Schlüssel identifiziert aufgrund seiner Eindeutigkeit den Eintrag (bei Datenbanken auch als Unique- oder Primary-Key bezeichnet). Wird ein weiterer Eintrag mit demselben Schlüssel eingefügt, wird nur der alte Wert des bestehenden Eintrags gegen den neuen ausgetauscht.
| Bei einer SortedMap sind die Einträge anhand eines Sortierkriteriums (Comparator) geordnet. |
| Ein Entry ist ein inneres Interface von Map, welches einen Eintrag kapselt und hierzu passende Methoden bereitstellt. |
In den Kommentaren zu den Interfaces sind Konventionen und Kontrakte enthalten, die nachfolgend kurz angesprochen werden sollen.
| Spezielle Ausnahmen vom Typ RuntimeException sollen bei konkreten Implementationen Kontraktverletzungen verhindern. |
Immutable Kollektionen dürfen keine Mutatoren enthalten, die die Kollektion nach der Anlage ändern. Deshalb sind die Mutatoren in Collection als optionale Methoden gekennzeichnet.
UnsupportedOperationException: unerwünschte Methode
Da aber Interfaces keine optionalen Methoden kennen, gilt folgende Konvention:
| UnsupportedOperationException: Diese Ausnahme soll von den unerlaubten optionalen Methoden ausgelöst werden. |
Löst eine Operation bzw. Methode diese Ausnahme nicht aus, wird sie grundsätzlich unterstützt.
ClassCastException:
unerwünschte Klasse
Will man Typen ausschließen, z.B. in einer Kollektion nur einen Typ von Objekten zulassen, lautet die Konvention:
| ClassCastException: Klasse ist nicht erlaubt. |
Für alle anderen Fällen, die eine Änderung der Kollektion ausschließen, gibt es:
IllegalArgumentException:
unerwünschter Aspekt
| IllegalArgumentException: Gewisse Aspekte verhindern eine Änderung. |
Ein Beispiel ist eine Kollektion, welche keine null-Elemente zulässt.
Bei Methoden mit Rückgabetyp boolean bedeutet der Rückgabewert false nicht, dass die Methode ungültig ist. Der Wert false hat abhängig vom Kontext folgende Semantik:
»nicht vorhanden«, »bereits enthalten« etc.Kontrakte beschreiben Abmachungen oder Verträge. Sie können informell sein (»es wäre schön, wenn ...«) oder in Form von Zusicherungen bzw. Constraints auftreten (siehe 6.12).
Es wäre schön, wenn zwischen compare() und equals() gilt:
o1.equals(o2)==true Û compare(o1,o2)==0
Werden informelle Kontrakte nicht eingehalten, sollte dies dem Anwender gegenüber klar ausgewiesen werden.
Constraints: unbedingter Kontrakt
| Verletzungen von Kontrakten in Form von Constraints dürfen dagegen erst gar nicht auftreten. |
Wenn man Glück hat, treten Kontraktverletzungen in Form von Laufzeitfehlern auf, wenn man Pech hat, führen sie zu semantischen Fehlern.
Da Interfaces keine Spezifikation von Constraints in der Form von Invarianten oder Pre- und Post-Konditionen kennen, haben die Designer zum Hilfsmittel »Kommentar« gegriffen.
Somit werden zu jeder Methode die Kontrakte in verbaler Form aufgeführt.3 Ein kurzes Beispiel (Tab. 14.1):
| Betreff | add()-Kontrakt bzw. -Constraints |
| Invariante | Kollektion enthält immer Element nach (normalem) Ablauf der Operation |
| Rückgabewert | true: Kollektion wurde geändert false: Kollektion enthält bereits Element und es sind keine Duplikate erlaubt (z.B. Set) |
| Ausnahmen | UnsupportedOperation: add() wird nicht unterstützt ClassCast: Klasse nicht erlaubt IllegalArgument: Gewisser Aspekt verhindert Einfügen (z.B. null-Wert) |
Wird ein Kontrakt wie in Tab. 14.1 formuliert bei der Implementation nicht eingehalten, führt dies z.B. bei einer Methode wie add() zu unterschiedlichen Ergebnissen, je nach dem, welche konkrete Klasse »hinter« dem Interface steht.
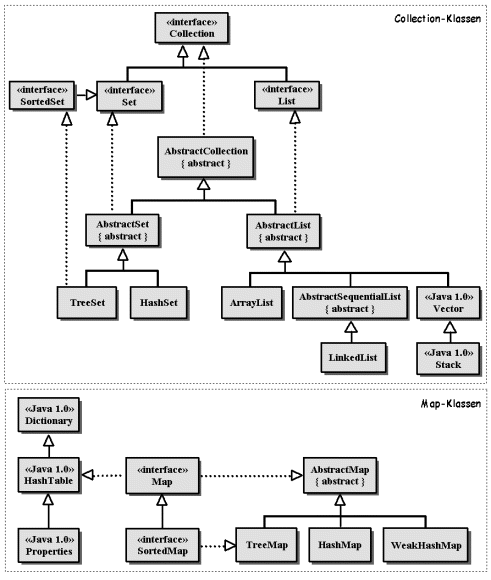
Bedingt durch das Interface-Framework unterteilen sich die Klassen-Implementationen in zwei Hierarchien (Abb. 14.4).
Klassen-
Hierarchie zum Framework
|
Die mit «Java 1.0» gekennzeichneten Legacy-Klassen sind in das neue Framework integriert worden, obwohl sie eigentlich überflüssig sind.4
Klonbar/Serialisierbar, keine
Synchronisation
Grundsätzlich sind alle neuen Klassen serialisierbar und können geklont werden, sind aber nicht synchronisiert.5
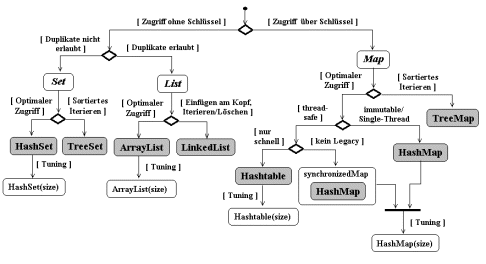
Zu den grundlegenden Typen Set, List und Map gibt es jeweils zwei Implementationen. Als primäre (Standard-)Implementationen werden die folgenden Klassen angesehen.
| HashSet: Basiert auf einer Hash-Tabelle, ist konstant schnell für die meisten Operationen, aber ungeordnet. |
| ArrayList: Basiert auf einem Array, das dynamisch wachsen kann, ist konstant schnell im Zugriff, dafür linear ansteigendes Zeitverhalten beim Einfügen von Elementen am Kopf. |
| HashMap: Analog zu Set. |
Bei der Wahl einer Klasse hilft ein Entscheidungsbaum (Abb. 14.5).
Entscheidungsbaum mit Auswahlkriterien
|
Tuning mit Hilfe von Konstruktoren
Sofern man wirklich optimale Performance haben möchte, können mit Ausnahme von LinkedList und Trees den Konstruktoren die Anfangsgröße und evtl. noch der Füllungsgrad übergeben werden (siehe »Hash-Kollektionen und Tuning«).
HashMap und somit HashSet, die intern eine Hashmap verwendet, erlauben den schnellsten Zugriff auf ihre Elemente.
Zugriffe sowie Einfügungen hängen allerdings von der optimalen Größe der Hash-Tabelle und dem maximalen Füllungsgrad ab.
| Bei Kenntnis der voraussichtlichen Anzahl der Elemente in einer Hash-Kollektion sollten die Default-Werte im Konstruktor mit optimalen Werten überschrieben werden. |
Die Grundlagen zu Hash-Tabellen und der Zusammenhang mit der hashCode()-Methode in Object wurde bereits in 10.1.3 und 10.1.4 behandelt.
Unter einem Bucket versteht man die Einträge im Hash-Array, d.h. die Liste mit den Elementen. Die Default-Anzahl der Buckets ist 11.

Tuning über
Füllungsgrad/Lastfaktor
Der Füllungsgrad bzw. Lastfaktor gibt an, wann die Hash-Tabelle vergrößert werden soll, um neue Einträge aufzunehmen. Somit ist loadFactor eine positive Zahl und hat den Default-Wert 0.75f (Typ float).
| Ein kleinerer loadFactor erhöht die Zugriffsgeschwindigkeit auf Kosten des benötigten Platzes. |
| Ein Rehashing ist sehr zeitintensiv und unbedingt zu vermeiden. |
Der Default-Füllungsgrad 0.75 ist in der Regel ein guter Kompromiss zwischen optimaler Zugriffszeit und Speicherplatzverbrauch.
Eine Vergrößerung der Anzahl der Buckets mit anschließendem Rehashing erfolgt nach den beiden Formeln:
numberOfElements > loadFactor * numberOfBuckets
newNumberOfBuckets= 2 * oldNumberOfBuckets + 1
Damit ergeben sich folgenden Performance-Regeln:
| 1. | Array-Anpassungen bzw. Rehashing wird vermieden, sofern gilt: |
| 2. | Primzahlen sind optimale Werte für numBuckets, da sie eine bessere Verteilung der Elemente auf die Buckets ergeben. Primzahlen mit besten Empfehlungen sind: |
89, 359, 719, 2879, 11519, 737279
| 3. | Hashcodes, die sich in der Kollektion ändern bzw. sehr häufig verwendet werden, müssen bzw. sollten als Feld separiert werden. |
Im ersten Test werden nur die ersten zwei Tuning-Regeln mit Hilfe von Strings getestet:
class Test { public static void main(String[] args) { //Set hs = new HashSet(); // :: 2200 //Set hs = new HashSet(23039); // :: 2180 //Set hs = new HashSet(200000); // :: 2050 Set hs = new HashSet(737279); // :: 1500
long t= System.currentTimeMillis(); for (int i= 0; i<100000; i++) hs.add("String"+i); System.out.println(System.currentTimeMillis()-t); } }
Beispiel zur
3. Regel bzw. zu einem informellen Kontrakt
Ergebnis: Nur die Kombination der ersten mit der zweiten Regel zeigt bei den Standard-Implementationen eine gute Wirkung.
Das nächste Beispiel verdeutlicht die dritte Regel bzw. das Zusammenspiel von hashCode() und equals().
class Element { String s; // mutable private int hashCode; // immmutable
public Element (String s) { this.s= s; hashCode= s.hashCode(); ¨ } /* Variation mit hashCode() public int hashCode() { return s.hashCode(); ¦ //return hashCode; Æ } */ // ignoriert Groß-/Kleinschreibung bei Test auf Gleichheit public boolean equals(Object o) { if (this==o) return true; // wie Object.equals() if (o==null || Element.class!=o.getClass()) return false; return s.equalsIgnoreCase(((Element)o).s); } }
Der Test bestätigt die Regeln in 10.1.3:
class Test { public static void main(String[] args) { Set hs = new HashSet(); Element e1= new Element("MutableElement"), e2= new Element("mutableElement"); hs.add(e1); e1.s= "mutableelement"; // e1 wird geändert! System.out.println(hs.contains(e1) // siehe unten! +" "+hs.contains(e2)); } }
Erklärung: Ohne die hashCode()-Variante kann man equals() weglassen. Denn Object.hashCode() liefert nur gleiche Werte für identische Instanzen. Folglich wird equals() immer nur für identische Objekte aufgerufen.
Variante: Erst mit der hashCode()-Methode wird die Sache interessant.
Zu ¨: Die Ausgabe ist false false, da die erste Regel aus 10.1.3 verletzt wird. e1 hat nach der Änderung nicht mehr denselben Hashcode.
Zu ¦: Die Ausgabe ist true false. Mit einem immutable Hash-Feld wird zumindest e1 wieder gefunden, e2 ist aber immer noch nicht gleich. Dies liegt aber an der Semantik in Zeile ¨.
Zu Æ: Die erste Regel aus 10.1.4 ist verletzt. Besser wäre wohl die folgende Anweisung gewesen:
hashCode= s.toLowerCase().hashCode();
Gleiche Semantik für equals() und hashCode()
Für Operationen wie Suchen, Einfügen und Entfernen von Elementen verwenden Hash-Kollektionen zuerst die hashCode()-Methode, um das Bucket zu bestimmen. Dann traversieren sie durch das Bucket, um mittels equals() das Element zu finden. Somit folgt:
| Zur equals()-Semantik muss immer die von hashCode() passen. |
Immutable
Hashcodes für Kollektionen
| Objekte, deren Hashcode sich ändert, während sie in der Kollektion sind, werden nicht wieder gefunden. |
Die letzte Implikation kann entweder durch ein Feld für den Hashcode behoben werden, das für die Dauer in der Kollektion immutable bleibt (siehe o.a. Beispiel), oder durch ein Rehash.
Generell erlaubt eine Map einen direkten Zugriff auf ein Objekt über einen assoziierten Schlüssel. Die Methoden zum Einfügen bzw. Lesen von Schlüssel/Wert-Einträgen sind die Methoden put() bzw. get().
Map hm= new HashMap(); hm.put("3-934358-01-2","JavaScript"); hm.put("Ch.Wenz","JavaScript"); hm.put("1-56592-455-x",null); // in Hashtable nicht erlaubt! hm.put("1-56592-455-x","JAVA Swing"); hm.put("0-201-54848-8","C++ Primer"); System.out.println(hm.get("1-56592-455-x")); // :: Java Swing
Collections-Sichten zur Map:
values() keySet() entrySet()
Eine Map kann durchaus wie eine Kollektion behandelt werden. Es stehen je nach Zweck drei alternative Methoden zur Verfügung:
Collection values(); // liefert die Werte als Kollektion Set keySet(); // liefert die Schlüssel als Menge Set entrySet(); // liefert die Einträge als Menge
Da Werte im Gegensatz zu Schlüsseln und Einträgen mehrfach vorkommen können, kann die erste Methode kein Set liefern.
System.out.println(hm.values()); // :: [C++ Primer, JAVA Swing, JavaScript, JavaScript] System.out.println(hm.keySet()); // :: [0-201-54848-8, 1-56592-455-x, Ch.Wenz, 3-934358-01-2] System.out.println(hm.entrySet()); // :: [0-201-54848-8=C++ Primer, 1-56592-455-x=JAVA Swing, Ch.Wenz=JavaScript, 3-934358-01-2=JavaScript] System.out.println(hm.remove("abc")); // :: null System.out.println(hm.remove("Ch.Wenz")); // :: JavaScript
| Die Reihenfolge in den drei Kollektionen ist nicht festgelegt. |
| Die drei Kollektionen zur Map sind keine Kopien, sondern liefern die Original-Objekte der Map. |
hm.values().remove("JavaScript"); // entfernt Originaleintrag hm.keySet().remove("1-56592-455-x"); // dito ((Map.Entry)hm.entrySet().iterator().next()).setValue("?");
System.out.println(hm.entrySet()); // :: [0-201-54848-8=?, 3-934358-01-2=JavaScript]
Liste: Elementzugriffe wie bei Arrays
Die Elemente in Listen sind wie bei Arrays indiziert. Im Gegensatz zu einem Array können Listen aber dynamisch wachsen und die Elemente können an beliebigen Stellen eingefügt und entfernt werden.
Man kann bei Listen zwischen den konkreten Implementationen ArrayList und LinkedList wählen.
Die Klasse ArrayList ist in der Regel die beste Wahl. Sie basiert intern auf Arrays und ist damit im Elementzugriff konstant schnell.
Wie bei der Hash-Tabelle kann im Konstruktor einer ArrayList die Anfangsgröße des internen Arrays gesetzt werden.
Der Default-Wert der Array-Größe ist 10. Reicht sie bei einem Neueintrag nicht aus, vergrößert sie sich um jeweils oldArraySize * 3 / 2 + 1, d.h. um ca. 50%.
Die interne Array-Größe ist damit wieder ein Tuning-Faktor.
Denn bei jeder Vergrößerung der ArrayList muss eine neues Array angelegt werden, die Elemente mittels System.arraycopy() kopiert und das alte Array vom Garbage-Collector entsorgt werden.
| Die anfängliche Größe einer ArrayList sollte etwa der Anzahl der aufzunehmenden Elemente entsprechen. |
| ArrayList ersetzt im neuen API die Legacy-Klasse Vector. |
ArrayList:
die neue Vector-Klasse
Vector ist grundsätzlich synchronisiert, ArrayList mit Hilfe des Wrappers Collections.synchronizedList() nur bei Bedarf (siehe Synchronisierte Wrapper) und hat die besseren Methoden sowie konsistentere Benennungen.
Für häufiges Einfügen oder Löschen am Anfang der Liste bzw. Iterieren mit gleichzeitigem Löschen ist LinkedList die geeignete Implementation, sofern kaum Zugriffe über den Index erfolgen.
LinkedList:
Verkettung mit Vor- und
Nachteilen
Die LinkedList speichert jedes Element separat mit einer Referenz auf den Vorgänger und Nachfolger und es gibt kein Tuning.
| Im Gegensatz zu ArrayList ist deshalb die eigentliche Einfüge- und Lösch-Operation am Kopf oder Ende der Liste gleich schnell. |
| Für jede Positionierung muss aber durch die Liste traversiert werden (im ungünstigsten Fall listSize/2-Operationen). |
Zusätzliche Methoden der LinkedList
Die LinkedList ist aufgrund von zusätzlichen Kopf-/Ende-Operationen gegenüber einer List besser für eine Queue6 oder eine DeQueue7 geeignet, da sie gerade hier geeignete Operationen zur Verfügung stellt:
addFirst() addLast() getFirst() getLast() removeFirst() removeLast()
Preis: Die Nutzung der Methoden wird damit bezahlt, dass die LinkList-Instanz nicht mehr generisch als List verwendet werden kann.
Probleme mit der Vererbung:
Queue/DeQueue
Will man auf Basis einer Liste eine Klassen-Hierarchie zu Queue und Dequeue implementieren, steht man schnell vor einem Problem:
class Queue extends LinkedList { ... } ¨ class Dequeue extends Queue { ... } ¦
oder vielleicht doch besser umgekehrt:
class Dequeue extends LinkedList { ... } Æ class Queue extends Dequeue { ... } Ø
Zu ¨ und Æ: Der Vorteil, alle passenden Methoden und deren Code einfach zu erben, geht mit dem gravierenden Nachteil einher, dass man auch alle unerlaubten Operationen übernimmt.
Also bleibt einem keine andere Wahl, als alle unerlaubten Operationen so zu überschreiben, dass sie z.B. eine IllegalMethodException auslösen. Dies gilt übrigens auch für Ø.
Und voilà der Code ist umfangreicher als der, den man ohne Vererbung zu schreiben hätte. Zusätzlich traktiert man den Anwender noch mit Ausnahmen.
Zu ¦: Bei dieser Vererbung können eigentlich alle Operationen von Queue in Dequeue übernommen werden, zu dem Preis, dass die Vererbung auf den Kopf gestellt wird.8
Bei eine Priority-Queue werden anhand einer Priorität Elemente hinter das letzte Element mit gleicher Priorität eingefügt. In diesem Fall greift die Vererbung:
class PriorityQueue extends Queue { ... }
Bis auf die add()-Methode sind alle Operationen gleich. Die folgenden Klassen beschränken sich nur auf die notwendigen Methoden:
Queue:
Implementation auf Basis von Delegation
class Queue { protected List l; // Delegation
public Queue () { l= new LinkedList(); } public Queue (List l) { // Flexibel! this.l= l!=null? l: new LinkedList(); } void add (Object o) { if (l instanceof LinkedList) ((LinkedList)l).addLast(o); else l.add(l.size(),o); } public Object remove() { if (l instanceof LinkedList) return ((LinkedList)l).removeFirst(); else return l.remove(0); } public boolean isEmpty() { return l.isEmpty(); } public String toString() { return l.toString(); } }
Priority-Objekte:
pro Interface-, contra Reflexions-Lösung
// Für PriorityQueue: Jedes Objekt braucht eine Priorität interface IPriority { int getPriority(); }
// Eine Hülle für Objekte in der PriorityQueue class PriorityWrapper implements IPriority { Object o; int p;
public PriorityWrapper (Object o, int priority) { p= priority; this.o= o; } public int getPriority() { return p; } public String toString() { return o.toString(); } }
Nachfolgend braucht die Klasse PriorityQueue nur die Methode add() zu überschreiben:
class PriorityQueue extends Queue { final int DEFAULT_PRIORITY;
public PriorityQueue () { this(0); }
public PriorityQueue (int defaultPriority) { // Für eine PriorityQueue ist eine ArrayList besser super(new ArrayList()); DEFAULT_PRIORITY= defaultPriority; }
Overriding von add(), Object-Check: IPriority oder Wrapper
void add(Object o) { int p; try { p= ((IPriority)o).getPriority(); // keine IPriority implementiert, dann Wrapper! } catch (ClassCastException e) { o= new PriorityWrapper(o,p= DEFAULT_PRIORITY); }
int i= l.size(); while (0<i && ((IPriority)l.get(i-1)).getPriority()<p) i--; l.add(i,o); } }
Abschließend ein kleiner Test zur Priority-Queue:
class Test { public static void main(String[] args) { PriorityQueue q= new PriorityQueue(); q.add(new PriorityWrapper("1",1)); q.add(new PriorityWrapper("2",2)); q.add(new PriorityWrapper("3",2)); q.add(new PriorityWrapper("4",1)); q.add("5"); // Default-Priorität 0 q.add(new PriorityWrapper("6",2)); System.out.println(q); // :: [2, 3, 6, 1, 4, 5] System.out.println(q.remove()); // :: 2 System.out.println(q); // :: [3, 6, 1, 4, 5] } }
Um für Objekte eine Ordnung zu definieren, bedient sich Java der Interfaces Comparable bzw. Comparator (siehe auch Abb. 14.3).
Comparable: natürliche Ordnung einer Klasse
| Hat eine Klasse eine so genannte natürliche Ordnung, nach der die Elemente sortiert werden können, implementiert die Klasse nach Java-Konvention das Interface Comparable: |
class ClassWithNaturalOrdering implements Comparable
Bekannte Beispiele sind die Klassen String, Date, BigDecimal und alle Wrapper-Klassen von primitiven Zahlentypen.
Zu der einzigen Methode des Interfaces Comparable
int compareTo(Object o);
o1.compareTo(o2) < 0 Û o1 < o2
o1.compareTo(o2)== 0 Û o1== o2
o1.compareTo(o2) > 0 Û o1 > o2
Bei Ungleichheit ist also nur das Vorzeichen für die Ordnung ausschlaggebend, nicht der Zahlenwert, und compareTo() und equals() sollten Gleichheit übereinstimmend definieren.
compareTo() und ClassCastException
Wie bei equals() muss die Implementierung natürlich zuerst die Objekt-Klassen auf Kompatibilität überprüfen, aber im Gegensatz zu equals() sollte sie bei Klassen-Unverträglichkeit mit einer ClassCastException reagieren (Konvention bei String etc.).
Comparator:
Definition von zusätzlichen Ordnungskriterien
| keine natürliche Ordnung oder |
| eine natürliche Ordnung, die man durch eine eigene ersetzen will, |
muss man den sortierten Kollektionen wie TreeSet oder Methoden wie Collections.sort() eine Instanz einer Klasse übergeben, die das
interface Comparator { int compare(Object o1, Object o2); }
implementiert. Die Methode compare() hat denselben Kontrakt wie compareTo() zu erfüllen, liefert also die o.a. Werte bei Objektvergleich.
TreeSet/TreeMap: sortiertes Einfügen
Muss nach jedem Einfügen eines Elements die Menge oder Map wieder sortiert sein, so kann man direkt auf eine sortierte Implementation wie TreeSet oder TreeMap zurückgreifen.
Das Einfügen von Elementen in eine sortierte Kollektion ist gegenüber einer unsortierten eine kostspielige Operation, da bis zu log2 n Vergleiche9 notwendig sind.
Alternative:
nur Sortieren bei Bedarf
| Alternativ kann man für Listen bzw. Arrays mit Hilfe der Methode Collections.sort() bzw. Arrays.sort() nachträglich nur dann sortieren, wenn es notwendig ist. |
TreeSet bzw. TreeMap implementiert zwei Interfaces SortedSet bzw. SortedMap, die äquivalente Operationen anbieten (siehe Abb. 14.1 und 14.2):
| Zugriff auf den Comparator, sofern definiert. |
| Zugriff auf das erste und letzte Element in der Sortierfolge, die durch Comparable oder Comparator definiert wurde. |
| Rückgabe eines Bereichs der Menge bzw. Map mit definiertem Anfangs- und Endpunkt. |
HashSet vs. TreeSet:
ein simpler Zeitvergleich
Zuerst ein Zeitvergleich zwischen HashSet und TreeSet:
long t; Set s1= new HashSet(), s2= new TreeSet();
t= System.currentTimeMillis(); for (int i=0; i<100000; i++) s1.add(new Integer((int)(100000.0*Math.random()))); Arrays.sort(s1.toArray()); System.out.println(System.currentTimeMillis()-t); // :: 1328
t= System.currentTimeMillis(); for (int i=0; i<100000; i++) s2.add(new Integer((int)(100000.0*Math.random()))); System.out.println(System.currentTimeMillis()-t); // :: 1531
Ergebnis: Selbst wenn eine HashSet nachträglich sortiert wird, ist dies noch schneller als direktes sortiertes Einfügen bei einer TreeSet.
Im folgenden Beispiel wird ein TreeSet einmal mit Teilen nach der Nummer sortiert, ein andermal nach der Bezeichnung sortiert gefüllt.
Teile-Klasse mit natürlicher Ordnung
class Teil implements Comparable { private int nr; // nur positiv! private String bez;
public Teil(int nr, String bez) { this.nr= Math.abs(nr); this.bez=bez; }
public int getNr() { return nr; } public String getBez() { return bez; } public void setString(String s) { bez= s; }
public int compareTo(Object t) { // natürliche Ordnung return nr - ((Teil)t).nr; // führt zu keinem Überlauf! } public String toString() { return nr+":"+bez; } }
class Test { public static void main(String[] args) { Teil [] tarr= new Teil[] { new Teil(7,"7"), new Teil(13,"13"), new Teil(20,"20"), new Teil(3,"3") };
System.out.println(new TreeSet(Arrays.asList(tarr))); // :: [3:3, 7:7, 13:13, 20:20]
Zusätzliche lexikographische Ordnung für
die Teile
Set s= new TreeSet( // anonyme Klasse, die nach Teilebezeichnung sortiert new Comparator() { ¨ public int compare(Object t1, Object t2) { return (Teil)t1).getBez().compareTo(((Teil)t2).getBez()); } });
s.addAll(Arrays.asList(tarr)); System.out.println(s); // :: [13:13, 20:20, 3:3, 7:7] } }
Zu ¨: Die natürliche Ordnung der ganzen Zahlen wurde durch eine Comparator-Instanz mit einer lexikographischen Ordnung ersetzt.

Kontrakt für Bereichs-Operationen
Das List-Interface hat nur eine subList()-Methode, die beiden Baumklassen bieten jeweils drei äquivalente Bereichs-Operationen sub<X>, head<X> und tail<X>. Es gelten folgende Kontrakt-Regeln:
| 1. | Bei allen Bereichs-Operationen werden keine Kollektionen mit neuen Elementen erschaffen, sondern es wird nur ein Ausschnitt aus der Original-Kollektion zurückgeliefert (ohne Elemente zu klonen). |
| 2. | Werden Elemente zu einer Teilkollektion hinzugefügt oder von ihr entfernt, betrifft dies die Original-Kollektion. |
| 3. | Werden Elemente zu einer Liste hinzugefügt oder von ihr entfernt, ist eine vorher mit subList() erschaffene Teilliste ungültig und löst bei Benutzung eine Ausnahme aus (siehe u.a. Beispiel). |
| 4. | Werden Elemente zu einem Baum hinzugefügt oder von ihm entfernt, sind die vorher erschaffenenen Teilbäume weiterhin gültig und enthalten ebenfalls die Änderung, sofern sie den Bereich betreffen. |
Der erste Test demonstriert die erste und zweite Regel:
class Teil implements Comparable { /* wie in Bäume (Trees) */ }
Bereich: ein nach oben halboffenes Intervall
class Test { public static void main(String[] args) { Teil [] tarr= new Teil[] { new Teil(7,"t0"), new Teil(13,"t1"), new Teil(20,"t2"), new Teil(3,"t3") };
SortedSet orgs= new TreeSet(Arrays.asList(tarr)); // die Bereichs-Operation schließt das // untere Element ein und das obere Element aus SortedSet sub1= orgs.subSet(tarr[3],tarr[2]); SortedSet sub2= orgs.headSet(tarr[2]); System.out.println(sub1); // :: [3:t3, 7:t0, 13:t1]
sub2.clear(); System.out.println(sub1); // :: []
System.out.println(orgs); // :: [20:t2] } }
Ergebnis: Es gibt nur eine Originalliste mit verschiedenen Sichten.
Im folgenden Test wird die dritte und vierte Regel demonstriert:
class Teil implements Comparable { /* wie in Bäume (Trees) */ }
class Test {
public static void main(String[] args) { Teil [] tarr= new Teil[] { new Teil(7,"t0"), new Teil(13,"t1"), new Teil(20,"t2"), new Teil(3,"t3") };
SortedMap orgm= new TreeMap(); for (int i=0; i<tarr.length; i++) orgm.put(new Integer(tarr[i].getNr()),tarr[i]);
SortedMap sub= orgm.tailMap(new Integer(7)); System.out.println(sub); // :: {7=7:t0, 13=13:t1, 20=20:t2}
// nach 4. Regel ok orgm.remove(new Integer(7)); System.out.println(sub); // :: {13=13:t1, 20=20:t2}
// Arrays.asList(tarr) ist immutable, deshalb: List l= new ArrayList(Arrays.asList(tarr));
// es gibt weiterhin nur vier Teile: geändert wird tarr[2] ((Teil)l.get(2)).setString("T2");
// diese Änderung reflektiert dann auch die Map System.out.println(orgm.get(new Integer(20))); // :: 20:T2
List subl= l.subList(1,3); System.out.println(subl); // :: [13:t1, 20:t2]
l.remove(0);
ConcurrentModificationException
// 3. Regel wird verletzt, erzeugt Ausnahme: System.out.println(subl); // :: java.util.ConcurrentModificationException // :: at ... } }
| Die vier o.a. Bereichs-Regeln können nicht von den Interfaces überprüft werden. Dies gilt ebenfalls für die Bereichs-Operationen, die nach Konvention das untere Element enthalten und das obere ausschließen. |
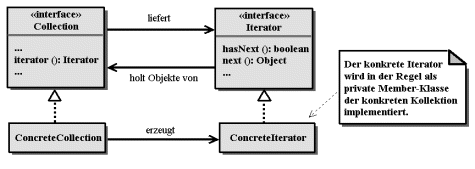
Iteratoren sind spezialisierte Adapter. Das Adapter-Muster wurde bereits in 9.12.3 vorgestellt und verwendet.
Das Iterator-Pattern separiert den sequenziellen Zugriff auf eine Kollektion vom Kollektions-Objekt selbst und verlagert es in ein Iterator-Objekt, das in der Regel von einem Iterator-Interface abgeleitet wird (Abb. 14.6).
|
Iteratoren als private Member-Klassen
Auch die im Collection-Framework enthaltenen Klassen folgen dem Muster und implementieren die Iteratoren als private Member-Klassen. Die Klasse HashMap enthält z.B. die Klasse HashIterator:
public class HashMap extends AbstractMap implements Map, Cloneable, java.io.Serializable { ... private class HashIterator implements Iterator { ... } }
| Da die Iterator-Member-Klasse private deklariert ist und ihre Objekte nur über Interface-Referenzen nach außen geliefert werden, bleibt die konkrete Iterator-Klasse opak. |
| Diese Umsetzung des Interface-Prinzips ist recht wirkungsvoll, da die Iteratoren nicht mehr als Klassen-Objekt (z.B. HashIterator) angesprochen werden können, sondern nur noch als Iterator. |
Das Iterator-Pattern sieht eigentlich keine Methoden zur Veränderung der Kollektionen vor.
Iterator: remove() zur Konvenienz
Hier weicht die Java-Umsetzung vom Muster ab, da im Iterator eine Methode remove() zur Konvenienz enthalten ist, die im veralteten Iterator Enumeration nicht enthalten war.
Ein wichtiger konzeptioneller Unterschied zu Indizes von Arrays ist die Art, wie Java-Iteratoren eine Kollektion durchlaufen:
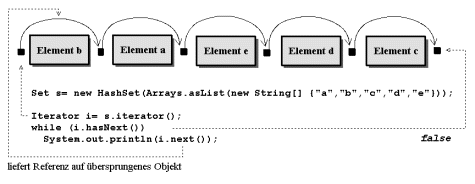
| Ein Iterator positioniert sich nicht wie ein Index auf einem Element, sondern vor einem Element und liefert die Referenz beim Überspringen (siehe Abb. 14.7). |
Wirkung der Methoden iterator(), hasNext() und next()
|
Iteratoren verhalten sich bei Entfernen von Elementen:
| 1. | Iteratoren (mit Ausnahme der Listen-Iteratoren) liefern die Elemente einer Kollektion in keiner fest vorgegebenen Reihenfolge. |
| 2. | Die Methode remove() entfernt das zuletzt mit next() übersprungene Element einer Kollektion. |
| 3. | Wird mehr als ein Iterator zur Kollektion erzeugt, werden durch einen Aufruf von remove() alle anderen Iteratoren ungültig, d.h., ihre weitere Benutzung führt zu einer ConcurrentModificationException. |
Zur ersten Regel: Die Rückgabe der Elemente ist bei einer Set nicht definiert:
Set s= new HashSet(Arrays.asList( new String[] {"a","b","c","d","e"})); Iterator i= s.iterator(); while (i.hasNext()) System.out.print(i.next()+" "); // :: b a e d c
Zur zweiten Regel: Ein Aufruf von remove() ohne vorhergehendes next() führt unweigerlich zu einer IllegalStateException:
Set s= new HashSet(Arrays.asList( new String[] {"a","b","c","d","e"})); Iterator i= s.iterator(); i.remove(); // ß Fehler, kein vorheriges next() while (i.hasNext()) i.remove(); // ß Fehler, dito
remove() bei mehreren
Iteratoren
Zur dritten Regel: Zwei Iteratoren und der Aufruf von remove():
Set s= new HashSet(Arrays.asList( new String[] {"a","b","c","d","e"})); Iterator i1= s.iterator(), i2= s.iterator(); i2.next(); i2.remove(); // i1 ist nun ungültig! System.out.println(i1.next()); // Ausnahme!
Diese letzte Einschränkung macht remove() ziemlich unsicher.
Da eine Map keine Kollektion ist, gibt es für eine Map nicht unmittelbar einen Iterator. Hier wählt man den Weg über eine der drei Kollektions-Sichten auf eine Map (siehe auch HashMap).
// class Teil implements Comparable { /* wie in Bäume (Trees) */ }
Teil[] tarr=new Teil[] {new Teil(7,"t0"),new Teil(13,"t1") ,new Teil(20,"t2"),new Teil(3,"t3")}; SortedMap map= new TreeMap(); for (int i=0; i<tarr.length; i++) map.put(new Integer(tarr[i].getNr()),tarr[i]);
for (Iterator i= map.entrySet().iterator(); i.hasNext();) ¨ System.out.print(((Map.Entry)i.next()).getValue()+" "); ¦
// :: 3:t3 7:t0 13:t1 20:t2
Zu ¨: In diesem Code-Fragment wird zu der Entry-Menge einer Map ein Iterator erzeugt.
Zu ¦: Die Objekte, die dann vom Iterator zurückgeliefert werden, sind Instanzen von Map.Entry, von denen mit getValue() die Objekte geholt werden können.
Die Methoden in den Interfaces lassen sich in zwei Gruppen einteilen:
Fundamentale und generische Algorithmen
| fundamentale Operationen, die sich nicht mit Hilfe eines Algorithmus aus den anderen ableiten lassen, |
| generische Algorithmen, die unabhängig von der Implementation nur mit Hilfe der fundamentalen Operationen geschrieben werden. |
Die generischen Algorithmen führen zu Template-Code bzw. Methoden, die nur Interface-Referenzen und nicht Klassen enthalten. Sie sind damit allgemein gültig, sofern nur der Kontrakt eingehalten wird.
Als Beispiel ein Original-Code aus der Klasse AbstractCollection:
public boolean contains(Object o) { Iterator e = iterator(); if (o==null) { while (e.hasNext()) if (e.next()==null) return true; } else { while (e.hasNext()) if (o.equals(e.next())) return true; } return false; }
Viele Templates bzw. generische Algorithmen, ob statisch oder nicht statisch, gehören eigentlich nicht in Klassen, sondern in die Interfaces, was aber in Java ausgeschlossen ist. Dieses Dilemma wird von den Designern wie folgt gelöst.
Abstract<X>-Klassen für generische Instanz-
Algorithmen
| als Instanz-Methoden sind in den abstrakten Klassen Abstract<X> enthalten.10 |
Collections-, Arrays-Klasse für statische generische Algorithmen
| als statischen Methoden sind in Collections bzw. Arrays enthalten. |
Im Plural der Namen ist angedeutet, dass beide Klassen eine Ansammlung von generischem Code für Kollektionen bzw. Arrays darstellen.
Deshalb sollte man sich beim Umgang mit Kollektionen an das folgende, nützliche Prinzip halten:
| Suche vor dem Codieren zuerst nach passenden Methoden in den Klassen Collections oder Arrays! |
Denn der Hauptvorteil dieser Templates gegenüber eigenem Code liegt in den klar definierten Eigenschaften, z.B. bei den folgenden Sortier-Operationen und der Robustheit des sorgfältig getesteten Codes.
In Bäume (Trees) wurde bereits eine Set nachträglich durch Umwandlung in ein Array mit Ausführung von Arrays.sort() sortiert.
sort(): stabil mit Performance
O(n log2 n)
Mit zwei sort()-Methoden der Klasse Collections lassen sich dagegen Listen mit Comparable bzw. Comparator sortieren.
| Der Sortier-Algorithmus in sort() ist ein modifizierter Mergesort, der eine garantierte Performance11 von O(nlog2n) hat und stabil ist. |
| Ein Sortier-Algorithmus heißt stabil, wenn er Elemente, die gleich12 sind, nicht umordnet. |
Neben der optimalen Performance ist Stabilität dann wichtig, wenn eine Sortierung einer anderen folgt (siehe hierzu das u.a. Beispiel).
Die beiden shuffle()-Methoden in Collections stellen inverse Operationen zum Sortieren dar. Sie erzeugen Listen, bei denen jede Permutation der Elemente als Liste mit gleicher Wahrscheinlichkeit auftreten kann, mit anderen Worten das Gegenteil von dem, was man unter Sortieren versteht.
Beispiel zum stabilen Sortieren:
Kundenname, Beträge
Die Faktura Rechnungen inkl. Gutschriften sollen, nachdem sie zuerst gemischt werden, nach Beträgen geordnet ausgegeben werden. Bei gleichen Beträgen sind die Kunden alphabetisch zu ordnen.
Es wird also zuerst nach Kundennamen sortiert und nachträglich nach Beträgen, sodass die alphabetische Reihenfolge bei gleichen Beträgen erhalten bleibt.
class KFaktura implements Comparable { private String kd; private double rBetr;
public KFaktura (String kunde, double rchBetrag) { kd= kunde; rBetr= rchBetrag; } public String getKunde() { return kd; } public double getBetrag(){ return rBetr; }
compareTo():
Ordnung nach Namen
public int compareTo(Object k) { // nicht sauber, aber einfach: kein Type-Check return kd.compareTo(((KFaktura)k).kd); } public String toString() { return kd+":"+rBetr; }
// Comparator als statische innere Klasse static class BetragComparator implements Comparator {
compare() in statische innere Klasse:
Ordnung nach Betrag
public int compare(Object f1, Object f2) { // Zugriff auf private Felder (wieder ohne Type-Check) double r=((KFaktura)f1).rBetr-((KFaktura)f2).rBetr; return r>0.? 1:(r==0.? 0:-1); } } } class Test { public static void main(String[] args) { KFaktura[] fArr= new KFaktura[] { new KFaktura("ABC AG",430.0),new KFaktura("CB eG",-10.0), new KFaktura("Kunz KG",323.0),new KFaktura("Otto GmbH",430.0), new KFaktura("PR OHG",-10.0),new KFaktura("WWW KGaA",323.0) };
List l= new ArrayList(Arrays.asList(fArr)); Collections.shuffle(l); System.out.println(l); Collections.sort(l); System.out.println(l); Collections.sort(l,new KFaktura.BetragComparator()); System.out.println(l); ¬ } }
Erklärung: Neben der »natürlichen« können weitere Ordnungen in der Klasse als statische Comparator-Klassen definiert werden. Dies hat neben dem Vorteil der klaren Zugehörigkeit den des direkten Zugriffs.
[PR OHG:-10.0, Otto GmbH:430.0, ABC AG:430.0, CB eG:-10.0, WWW KGaA:323.0, Kunz KG:323.0] [ABC AG:430.0, CB eG:-10.0, Kunz KG:323.0, Otto GmbH:430.0, PR OHG:-10.0, WWW KGaA:323.0] [CB eG:-10.0, PR OHG:-10.0, Kunz KG:323.0, WWW KGaA:323.0, ABC AG:430.0, Otto GmbH:430.0] |
Wie in der Ausgabe zu Zeile ¨ zu sehen, bleibt bei gleichen Beträgen die alphabetische Ordnung nach Kundennamen erhalten, die durch das vorherige Sortieren erreicht wurde.
Die Klasse Collections enthält außer für Sortieren und Mischen noch weitere interessante Methoden, insbesondere für Listen.
Binäres Suchen mit binarySearch()
int binarySearch(List list, Object element); int binarySearch(List list, Object element, Comparator c)
suchen in einer aufsteigend geordneten Liste aufgrund der definierten natürlichen Ordnung bzw. der der Comparator-Instanz das angegebene Objekt.
| Ist das Objekt in der Liste, wird der Index des Objekts in der Liste zurückgegeben. |
| Ist ein Objekt mehrfach vorhanden, wird der Index irgendeines dieser Objekte zurückgegeben (d.h. nicht unbedingt des ersten). |
| Ist das Objekt nicht in der Liste, wird (insertionIndex+1) zurückgegeben, wobei mit insertionIndex der Einfügepunkt gemeint ist (an dem das Objekt stehen müsste). |
| Ist die Liste nicht sortiert, ist das Ergebnis schlichtweg falsch. |
Die Performance liegt zwischen log2n und linear im worst case für Subklassen der AbstractSequentialList.
Beispiel: binäre Suche in einer ArrayList
List l= new ArrayList(Arrays.asList( new String[] { "should", "be", "sorted", "to", "find","this","object"})); Collections.sort(l); int pos= Collections.binarySearch(l,"Object"); System.out.println(pos);
l.add(pos>0?pos:-pos-1,"Object");
System.out.println(l);
System.out.println(Collections.binarySearch(l,"Object")); System.out.println(Collections.binarySearch(l,"OBJECT", String.CASE_INSENSITIVE_ORDER)); // String-Comparator
-1 [Object, be, find, object, should, sorted, this, to] 0 3 |
void copy (List destination, List source); void fill (List list, Object element); void reverse(List l);
kopieren, füllen oder kehren eine Liste um.
Bei der Kopier-Operation muss die Liste destination mindestens die Länge von source haben, sonst erhält man eine IndexOutOfBoundsException. Ist sie länger, bleiben die überzähligen Elemente erhalten.
Immutable
Singleton- Kollektionen
Set singleton (Object element); List singletonList(Object element); Map singletonMap (Object key, Object value);
liefern eine immutable Set, List oder Map, was ab und an nützlich ist.
Wie bereits durch das Decorator-Pattern (11.7) hinlänglich bekannt, fügt ein Wrapper eine zusätzliche Eigenschaft zu dem Objekt hinzu, das er einhüllt.
Dies kann allerdings auch auf ein Entfernen unerwünschter Eigenschaften hinauslaufen (siehe Immutable Wrapper).
Synchronisierte Wrapper für jedes Interface
Kollektionen in ihrer Grundform sind nicht thread-sicher (siehe 9.5.2). Deshalb enthält die Klasse Collections sechs Methoden,
Collection synchronizedCollection(Collection c); Set synchronizedSet (Set s); List synchronizedList (List list); SortedSet synchronizedSortedSet (SortedSet s); Map synchronizedMap (Map m); SortedMap synchronizedSortedMap (SortedMap m);
die für jedes Interface im Framework einen thread-sicheren Wrapper zurückliefern.
Design-Schwäche des Decorator-Patterns
Die erste Frage ist wohl, warum sechs und nicht zwei Methoden für Collection bzw. Map, da doch alle anderen von ihnen abgeleitet sind?
Die Anwort offenbart eine Design-Schwäche des Decorator-Patterns bzw. von Wrappern.
Dekoriert werden nur Methoden der Klasse bzw. des Interfaces, die dem Decorator a priori zum Entwicklungs- bzw. Compile-Zeitpunkt bekannt sind. Der Wrapper reagiert nicht auf neue Methoden der Subklassen bzw. Sub-Interfaces, denn er kennt sie gar nicht.
| Im Fall der Synchronisation werden also nur die Methoden des übergebenen Interfaces durch den Wrapper synchronisiert, neue Subklassen/Sub-Interface-Methoden nicht. |
Lock auf Wrapper-Objekt in jeder einzelnen Methode
Die zurückgelieferten Kollektionen sind Instanzen von gleichnamigen synchronisierten statischen inneren Klassen von Collections, z.B.:
static class SynchronizedCollection implements Collection,
Serializable {}
Die Synchronisation erfolgt in jeder Methode der neuen Instanz der Synchronized<X>-Klasse, und zwar nicht auf der Original-Kollektion, sondern auf dem Wrapper-Objekt. Dies bedeutet:
Vorsicht bei Referenz auf
Original- Kollektion
| Die übergebenen Kollektionen können weiterhin parallel zu den neuen benutzt werden (natürlich unsynchronisiert!), sofern sie nur referenziert werden können. |
| Iteratoren zu einem synchronisierten Wrapper sind nicht thread-sicher, d.h., jeder Iterationsschritt wird nur einzeln synchronisiert und nicht etwa die gesamte Iteration. |
Dies ist bei einem Thread-Safe-Design unbedingt zu berücksichtigen.
Der zweite Punkt führt zu folgendem Idiom als Template-Code, wobei <X> für eines der sechs Interfaces steht.
<X> syncC= Collections.synchronized<X>(c); ... // nur wenn <X> eine Map oder SortedMap ist // eine von den drei Kollektions-Sichten // Set s= syncC.keySet(); // Set s= syncC.values(); // Set s= syncC.entrySet(); ... synchronized(syncC) { for (Iterator i= syncC.iterator(); i.hasNext();) ¨ //for (Iterator i= s.iterator(); i.hasNext();) ¦ System.out.println(i.next()); }
Ist <X> eine der beiden Maps, muss erst eine Set s erzeugt werden und Zeile ¨ durch Zeile ¦ ersetzt werden. Wichtig ist, dass nicht auf s, sondern auf syncC synchronisiert wird.
Collection c= new HashSet(); ... Collection syncC= Collections.synchronizedCollection(c); ... synchronized(syncC) { for (Iterator i= syncC.iterator(); i.hasNext();) operateOn(i.next()); }
Immutable Wrapper:
unveränderbare Kollektion
Alles, was zu den synchronisierten Wrappern angeführt wurde, gilt auch für die immutable Wrapper. Sie liefern eine Kollektion zurück, die nicht geändert werden kann und sind damit für alle Clients nützlich, die nur lesen dürfen.
Es gibt wieder sechs Wrapper-Methoden in Collections mit den bereits in Synchronisierte Wrapper beschriebenen Restriktionen:
Collection unmodifiableCollection(Collection c); Set unmodifiableSet (Set s); List unmodifiableList (List list); SortedSet unmodifiableSortedSet (SortedSet s); Map unmodifiableMap (Map m); SortedMap unmodifiableSortedMap (SortedMap m);
Mutable Operationen lösen
Ausnahmen aus
Da immutable Wrapper konzeptionell keine Methoden aus dem Interface entfernen können, liefern alle nicht lesenden Methoden des Wrappers wie z.B. remove() eine UnsupportedOperationException.
Vorsicht bei Referenz auf
Original- Kollektion
| Will man den Clients wirklich nur lesenden Zugriff auf eine Kollektion gewähren, dürfen sie keine Referenz auf die Original-Kollektion erhalten. |
Das Collection-Framework bietet wegen seiner späten Geburt sehr flexible Möglichkeiten der Verwendung.
Aufgrund seiner interface-basierten Konzeption kann es einerseits für eigene Klassen-Hierarchien genutzt werden, andererseits bietet es aber auch durch ein begleitendes Klassen-Framework konkrete Implementationen für alle Interfaces.
Die Auswahl der konkreten Klasse geschieht anhand von Anforderungen, die sich neben den geforderten Eigenschaften auch an Performance-gesichtspunkten orientieren. Diese werden im Detail zusammen mit einem Entscheidungsbaum zur Auswahl einer konkreten Klasse vorgestellt.
Die einzelnen Implementationen werden besprochen und die wichtigsten Eigenschaften zusammen mit Regeln und anhand von Code-Fragmenten demonstriert.
Viele Kollektionen benötigen eine Ordnung. Anhand der Interfaces Comparable und Comparator werden natürliche und ergänzende Ordnungen einer Klasse besprochen.
Bei Sortierungen ist neben der Performance insbesondere die Stabilität wichtig, was an einem praktischen Beispiel demonstriert wird.
Generische Algorithmen in den Klassen Arrays und insbesondere Collections bilden zusammen mit den Dekoratoren für Synchronisation und unveränderbare Kollektionen den Abschluss des Kapitels.
An relevanten Stellen wird auf das unverzichtbare Kontrakt-Management hingewiesen, was leider in Form von Constrains in jede einzelne Klasse implementiert werden muss.
Die konzeptionelle Problematik, die damit verbunden ist, bildet die eigentliche Achillesferse des Collection-Frameworks, was allerdings an der Sprache Java selbst liegt.
Zu jeder Frage können jeweils eine oder mehrere Antworten bzw. Aussagen richtig sein.
A: Die Interface-Hierarchie des Collections-Frameworks beruht auf einfacher Interface-Vererbung.
B: Die Hierarchie des Collections-Frameworks hat nur ein Basis-Interface, von dem alle anderen als Sub-Interfaces abgeleitet werden.
D: Keine der mit dem Collections-Framework in Java 1.2 neu eingeführten Klassen ist synchronisiert und immutable.
E: Bei allen von Tree abgeleiteten Klassen werden die Elemente bzw. Einträge sortiert eingefügt.
F: Die Elemente bzw. Einträge in einer HashSet bzw. HashMap sind nicht sortiert.
G: Zu jedem Interface im Collections-Framework gibt es einen Iterator.
H: Zu allen Klassen und Interfaces der Collection-Hierarchie gibt es einen Iterator.
I: Bei ListIterator ist die Reihenfolge, in der die Elemente mit next() geliefert werden, nicht festgelegt.
J: Die Map hat drei Methoden, die alle ihre Einträge als Typ Set zurückliefern.
K: Die Map hat eine Methode, die ihre Einträge als Typ Collection zurückliefert.
L: Auf alle Referenzen vom Typ Collection kann gleichzeitig von mehreren Iteratoren zugegriffen werden, sofern sie nicht remove() ausführen.
M: Vor jeder Ausführung von remove() muss bei einem Iterator vorher ein next() ausgeführt werden.
N: Die Ausführung von remove() bei einem Iterator führt bei Ausführung irgendeiner Methode eines anderen Iteratoren derselben Kollektion zu einer Ausnahme.
String s= "A"; Collection c= new HashSet(); c.add("A"); c.add("A"); ¨ c.add(s); System.out.println(c);
Collection c= new HashSet(); c.add("a"); c.add("b"); c.add("c"); for (Iterator i= c.iterator(); i.hasNext();) ¨ System.out.print(i.next());
B: Die Ausgabe erfolgt nicht in der Reihenfolge des Einfügens der Elemente.
Collection c= new HashSet(); c.add("a"); c.add("b"); c.add("c"); for (Iterator i= c.iterator(); i.hasNext();) i.remove(); ¨ System.out.println(c);
Map m= new HashMap(); m.put("1","Teil1"); m.put("2","Teil2"); m.put("2","Teil3"); ¨ System.out.println(m);
Map m= new HashMap(); m.put("1","Teil1"); m.put("2","Teil1"); m.put("3","Teil1"); Iterator i= m.values().iterator(); ¨ while (i.hasNext()) System.out.print(i.next()+" ");
List l= new ArrayList(Arrays.asList( new String[] {"A","B","C","D"})); Collections.shuffle(l); System.out.println(l); ¨ Collections.sort(l, new Comparator() { public int compare(Object s1, Object s2) { return -((String)s1).compareTo((String)s2); } }); System.out.println(l); ¦
A: Die Ausgabe von Zeile ¨ enthält eine Permutation der Buchstaben A, B, C und D.
1 Sieht man die potenziellen Möglichkeiten, wird die Sprachdefinition von Interfaces nach mehreren Jahren Java-Evolution langsam ärgerlich.
2 Dies bedeutet, dass compare() konsistent zu equals() sein sollte, d.h. dann Null liefert, wenn equals() den Wert true zurückgibt.
3 Dies ist nicht nur äußerst informell, sondern führt dazu, dass alle Methoden im Interface Set wegen der Kommentare noch einmal aufgeführt werden, obwohl Set überhaupt keine neuen Methoden gegenüber Collection definiert.
4 Legacy-Code, aus der Vergangenheit geerbter Code, erfreut sich durch rege Verwendung meist eines langen Lebens und wurde deshalb geschickt erweitert, um in das neue Framework zu passen. Er wird hier nicht weiter behandelt.
5 Diese Aussage gilt nicht für Legacy-Klassen wie Vector und Hashtable. synchronized ist bei einer Interface-Hierarchie auch schlecht möglich, da bei Interfaces nicht erlaubt.
6 Queue (Warteschlange): Eine Liste, bei der nur vom Kopf Elemente entfernt und am Ende der Liste hinzugefügt werden dürfen.
7 DeQueue: Eine Liste, bei der nur an beiden Seiten (Kopf und Ende) Elemente entfernt und hinzugefügt werden dürfen.
8 Sollten die einzig möglichen Einfüge/Lösch-Operationen in Queue übrigens add() bzw. remove() lauten, haben sie in Dequeue zweideutige Namen, da sie hier addLast() bzw. removeFirst() heißen müssten. Not amusing!
9 Bei n Einträgen und einer Implementation als binärer Baum.
10 Will man also Template-Code zu Instanz-Methoden nicht selbst schreiben, muss man seine Klassen von Abstract<X> ableiten (eine verdammt unschöne Lösung!).
11 Performance wird in der Big O-Notation angegeben. O(f(n)) bedeutet, dass ab einer großen Zahl n etwa f(n) Operationen notwendig sind, präziser:
g(n)= O(f(n)) Û es existiert ein Konstante k und ein n0 mit g(n) <= k f(n) für n >= n0.
| << zurück |
| |||||
| |||||
| |||||
| |||||
| |||||
| |||||
| |||||
| |||||
Copyright © Galileo Press GmbH 2001 - 2002
Für Ihren privaten Gebrauch dürfen Sie die Online-Version natürlich ausdrucken und speichern. Ansonsten unterliegt das <openbook> denselben Bestimmungen wie die gebundene Ausgabe: Das Werk einschließlich aller seiner Teile ist urheberrechtlich geschützt. Alle Rechte vorbehalten einschließlich der Vervielfältigung, Übersetzung, Mikroverfilmung sowie Einspeicherung und Verarbeitung in elektronischen Systemen.
Die Veröffentlichung der Inhalte oder Teilen davon bedarf der ausdrücklichen schriftlichen Genehmigung von Galileo Press. Falls Sie Interesse daran haben sollten, die Inhalte auf Ihrer Website oder einer CD anzubieten, melden Sie sich bitte bei: stefan.krumbiegel@galileo-press.de




 bestellen
bestellen
