
 |
|
|
|||||
Ist der Parameter append mit true belegt, so wird der zu schreibende Inhalt an die Datei angehängt. Andernfalls wird der Inhalt überschrieben. Das nachfolgende Programm erfragt über einen grafischen Dialog eine Eingabe und schreibt diese in eine Datei: Listing 12.8 BenutzereingabeSchreiben.java import java.io.*; import javax.swing.JOptionPane; public class BenutzereingabeSchreiben { public static void main( String args[] ) { byte buffer[] = new byte[80]; try { String s; while ( ( s = JOptionPane.showInputDialog( "Gib eine nette Zeile ein:" )) = = null ); FileOutputStream fos = new FileOutputStream( "c:/line.txt" ); fos.write( s.getBytes() ); fos.close(); } catch ( Exception e ) { System.out.println(e); } } } 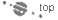 12.4.4 Die Eingabeklasse InputStream
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
abstract class java.io.InputStream |
| int available() Gibt die Anzahl der verfügbaren Zeichen im Datenstrom zurück, die sofort ohne Blockierung gelesen werden können. |
| int read() Liest ein Byte als Integer aus dem Datenstrom. Ist das Ende des Datenstroms erreicht, wird -1 übergeben. Die Funktion ist überladen, wie die nächsten Signaturen zeigen. |
| int read( byte b[] ) Mehrere Bytes werden in ein Feld gelesen. Die tatsächliche Länge der gelesenen Bytes wird zurückgegeben. |
| int read( byte b[], int off, int len ) Liest den Datenstrom in ein Bytefeld, schreibt ihn aber erst an der Stelle off in das Bytefeld. Zudem begrenzt len die maximale Anzahl von zu lesenden Zeichen. |
| long skip( long n ) Überspringt eine Anzahl von Zeichen. |
| void mark( int readlimit ) Merkt sich eine Position im Datenstrom. |
| boolean markSupported() Gibt einen Wahrheitswert zurück, ob der Datenstrom das Merken und Zurücksetzen von Positionen gestattet. Diese Markierung ist ein Zeiger, der auf bestimmte Stellen in der Eingabedatei zeigen kann. |
| void reset() Springt wieder zurück zur Position, die mit mark() gesetzt wurde. |
| void close() Schließt den Datenstrom. |
Gelingt eine Durchführung nicht, bekommen wir eine IOException.
Bisher haben wir die grundlegenden Ideen der Stream-Klassen kennen gelernt, aber noch kein echtes Beispiel. Dies soll sich nun ändern. Wir wollen für einfache Dateieingaben die Klasse FileInputStream verwenden (FileInputStream implementiert InputStream). Wir binden mit dieser Klasse eine Datei (etwa repräsentiert als ein Objekt vom Typ File) an einen Datenstrom.
Hier klicken, um das Bild zu Vergrößern
class java.io.FileInputStream extends InputStream |
Um ein Objekt anzulegen, haben wir die Auswahl zwischen drei Konstruktoren:
| FileInputStream( String name ) Erzeugt einen FileInputStream mit einem gegebenen Dateinamen. Der richtige Dateitrenner, zum Beispiel »\« oder »/«, sollte beachtet werden. |
| FileInputStream( File file ) Erzeugt FileInputStream aus einem File-Objekt. |
| FileInputStream( FileDescriptor fdObj ) Erzeugt FileInputStream aus einem FileDescriptor-Objekt. |
Ein Programm, welches seinen eigenen Quellcode anzeigt, sieht wie folgt aus:
Listing 12.9 ReadQuellcode.java
import java.io.*; public static void main( String args[] ) { String filename = "ReadQuellcode.java"; byte buffer[] = new byte[ 4000 ]; FileInputStream in = null; try { in = new FileInputStream( filename ); int len = in.read( buffer, 0, 4000 ); String str = new String( buffer, 0, len ); System.out.println( str ); } catch ( IOException e ) { System.out.println( e ); } finally { try { if ( in != null ) in.close(); } catch (IOException e) {} } } }
Zunächst reserviert das Programm ein fixes Bytefeld mit 4 KB. Anschließend wird versucht, 4.000 Zeichen in das Bytefeld einzulesen. Die genaue Anzahl der gelesenen Zeichen liefert die Rückgabe von read(). Anschließend wird das Bytefeld in ein String konvertiert und dieser ausgegeben.
Um die gesamte Datei einzulesen, müssen wir vorher die Dateigröße kennen. Dazu lässt sich length() der File-Klasse nutzen. Und wenn ein File-Objekt sowieso schon angelegt ist, lässt sich damit auch gleich die Datei öffnen.
File f = new File( Dateiname ); byte buffer[] = new byte[ (int) f.length() ]; in = new FileInputStream( f );
Die Klasse java.io.FileDescriptor repräsentiert eine offene Datei oder eine Socket-Verbindung mittels eines Deskriptors. Er lässt sich bei File-Objekten mit getFD() erfragen; bei Socket-Verbindungen allerdings nicht über eine Funktion - nur Unterklassen von SocketImpl (und DatagramSocketImpl) ist der Zugriff auf eine protected Methode getFileDescriptor() zugesagt.
In der Regel kommt der Entwickler nicht mit einem FileDescriptor-Objekt in Kontakt. Es gibt allerdings eine Anwendung, in der die Klasse FileDescriptor nützlich ist: Sie bietet eine sync()-Funktion an, die verbleibende Speicherblöcke auf das Gerät schreibt. Damit lässt sich erreichen, dass Daten auch tatsächlich auf dem Datenträger materialisiert werden.
Neben FileInputStream kennen auch FileOutputStream und RandomAccessFile eine Funktion getFD(). Mit einem FileDescriptor kann auch die Arbeit zwischen Stream-Objekten und RandomAccessFile-Objekten koordiniert werden.
Als Beispiel für das Zusammenspiel von FileInputStream und FileOutputStream wollen wir nun ein Datei-Kopierprogramm entwerfen. Es ist einleuchtend, dass wir zunächst die Quelldatei öffnen müssen. Taucht ein Fehler auf, wird dieser zusammen mit allen anderen Fehlern in einer besonderen IOException-Fehlerbehandlung ausgegeben. Wir trennen hier die Fehler nicht besonders. Nach dem Öffnen der Quelle wird eine neue Datei angelegt. Das machen wir einfach mit FileOutputStream. Der Methode ist es jedoch ziemlich egal, ob es schon eine Datei mit diesem Namen gibt, da sie diese gnadenlos überschreibt. Auch darum kümmern wir uns nicht. Wollten wir das berücksichtigen, sollten wir mit Hilfe der File-Klasse die Existenz einer Datei mit dem gleichen Namen prüfen. Doch wenn alles glatt geht, lassen sich die Bytes kopieren. Der naive und einfachste Weg liest jeweils ein Byte ein und schreibt dieses.
Es muss nicht extra erwähnt werden, dass die Geschwindigkeit dieses Ansatzes erbärmlich ist. Das Puffern in einen BufferedInputStream beziehungsweise Ausgabestrom ist in diesem Fall unnötig, da wir einfach einen Puffer mit read(byte[]) füllen können. Da diese Methode die Anzahl tatsächlich gelesener Bytes zurückliefert, schreiben wir diese direkt mittels write() in den Ausgabepuffer. Hier bringt eine Pufferung über eine Zwischen-Puffer-Klasse keine zusätzliche Geschwindigkeit ein, da wir ja selbst einen 64 KB-Puffer einrichten.
Listing 12.10 FileCopy.java
import java.io.*; public class FileCopy { static void copy( String src, String dest ) { try { copy( new FileInputStream( src ), new FileOutputStream( dest ) ); } catch( IOException e ) { System.err.println( e ); } } static void copy( InputStream fis, OutputStream fos ) { try { byte buffer[] = new byte[0xffff]; int nbytes; while ( (nbytes = fis.read(buffer)) != -1 ) fos.write( buffer, 0, nbytes ); } catch( IOException e ) { System.err.println( e ); } finally { if ( fis != null ) try { fis.close(); } catch ( IOException e ) {} try { if ( fos != null ) fos.close(); } catch ( IOException e ) {} } } public static void main( String args[] ) { if ( args.length < 2 ) System.out.println( "Usage: java FileCopy <src> <dest>" ); else copy( args[0], args[1] ); } }
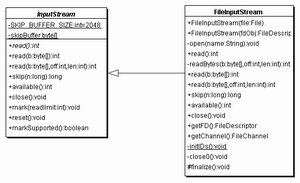
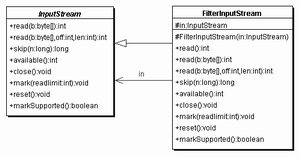
Die Daten, die durch irgendwelche Kanäle zum Benutzer kommen, können durch zwei spezielle Klassen gefiltert werden: FilterInputStream und FilterOutputStream. Eine Filter-Klasse überschreibt alle Methoden von InputStream und OutputStream und ersetzt diese durch neue Methoden mit erweiterter Funktionalität. Beispielsweise ist der FilterInputStream die Basis für BufferedInputStream (Daten puffern), CheckedInputStream (Daten mit Checksumme versehen), DataInputStream (primitive Datentypen lesen), DigestInputStream (Hash-Wert mitberechnen), InflaterInputStream (entpacken von Daten), LineNumberInputStream (mitzählen von Zeilen) und PushbackInputStream (Daten in den Lesestrom zurückgelegt). Die Klasse LineNumberInputStream sollte nicht mehr verwendet werden, da sie veraltet ist.
Hier klicken, um das Bild zu Vergrößern
Am UML-Diagramm fällt besonders auf, dass jeder Filter selbst ein Stream ist und zum anderen einen Stream verwaltet. Damit nimmt er Daten entgegen und leitet sie gleich weiter. Das ist ein bekanntes Design-Pattern und nennt sich Dekorator.
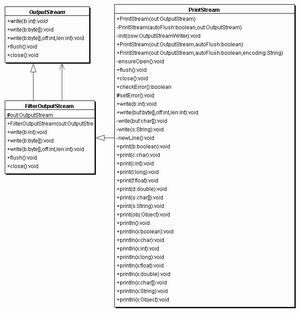
Schon in den ersten Programmen haben wir ein PrintStream-Objekt verwendet - doch vermutlich, ohne es zu wissen. Es steckte im out-Attribut der Klasse System. Es sind die vielen überladenen println()- und print()-Funktionen, die auf allen Datentypen operieren. So ist auch die Aufgabe definiert: Ausgabe unterschiedlicher Daten mittels einer überladenen Funktion. Im Gegensatz zum DataOutputStream erzeugt das PrintStream auch keine IOException. Intern setzt die Klasse jedoch ein Flag, welches durch die Methode checkError() nach außen kommt. Technisch gesehen ist ein PrintStream ein FilterOutputStream. So wie jeder Filter muss ein PrintStream-Objekt mit einem Ausgabeobjekt verbunden sein. Im Konstruktor kann zusätzlich noch ein Auto-Flush übergeben werden, das bestimmt, ob die Daten bei einem println() - oder beim Byte »\n« in der Zeichenkette - aus dem Puffer gespült werden. Alle Methoden sind synchronized, und die Ausgabemethoden passen die Zeichenketten an die jeweilige Kodierung an.
class java.io.PrintStream extends FilterOutputStream |
| PrintStream( OutputStream out, boolean autoFlush ) Erzeugt einen neuen PrintStream, der automatisch beim Zeilenende den Puffer leert. |
| PrintStream( OutputStream out ) Erzeugt einen neuen PrintStream. |
| boolean checkError() Testet, ob intern eine IOException aufgetreten ist. |
| void close() Schließt den Stream. |
| void flush() Schreibt den Puffer. |
| void print( boolean|char|char[]|double|float|int|long|String ) Schreibt die primitiven Daten, String und Char-Feld. |
| void print( Object o ) Ruft o.toString() auf und gibt das Ergebnis aus, wenn o ungleich null ist. Sonst ist die Ausgabe null. |
| void println() Schließt die Zeile mit einem Zeilenendezeichen ab. |
| void println( boolean|char|char[]|double|float|int|long|String|Object ) Wie oben, schließt aber die Zeile mit einem Zeilenendezeichen ab. |
| protected void setError() Setzt den Fehlerstatus auf true. |
| void write( byte buf[], int off, int len ) Schreibt len Bytes des Felds ab off in den Datenstrom. |
| void write( int b ) Schreibt Byte b in den Datenstrom. |
Hier klicken, um das Bild zu Vergrößern
Für die Standardeingabe- und Ausgabegeräte, die normalerweise Tastatur und Bildschirm sind, sind zwei besondere Stream-Klassen definiert, die beim Laden der Klasse automatisch erzeugt werden und von uns genutzt werden können. Dies ist zum einen das Objekt System.in für die Eingabe und zum anderen das Objekt System.out für die Ausgabe. System.in ist ein Exemplar der Klasse InputStream (genauer gesagt vom Typ BufferedInputStream) und System.out beziehungsweise System.err ein Exemplar von PrintStream.
| Beispiel Ein Programm, das eine Benutzereingabe einliest und anschließend auf den Bildschirm schreibt. |
Listing 12.11 KonsolenHinUndHer.java
public class KonsolenHinUndHer { public static void main( String args[] ) { System.out.println( "\nGib mir eine Zeile Text: " ); byte buffer[] = new byte[255]; try { System.in.read( buffer, 0, 255 ); } catch ( Exception e ) { System.out.println( e ); } System.out.println( "\nDu hast mir gegeben: "); System.out.println( new String(buffer) ); } }
final class java.lang.System |
| InputStream in Dies ist der Standardeingabestrom. Er ist immer geöffnet und nimmt die Benutzereingaben normalerweise über die Tastatur entgegen. |
| PrintStream out Der Standardausgabestrom. Er ist immer geöffnet und normalerweise mit der Bildschirmausgabe verbunden. |
| PrintStream err Der Standard-Fehlerausgabestrom. Er wurde eingeführt, um die Fehlermeldungen von den Ausgabemeldungen zu unterscheiden. Auch wenn der Ausgabekanal umgeleitet wird, bleiben diese Meldungen erreichbar. |
Für Applikationen ist es nur möglich, über die oben genannten Methoden die Standardeingabe auf einen beliebigen InputStream und die Standardausgabe auf einen beliebigen PrintStream umzuleiten. Bei einem Applet bekommen wir eine Security-Exception, da keine Ausgaben unterdrückt werden dürfen. Zum Ändern dienen die Methoden setIn(), setOut() und setErr().
final class java.lang.System |
| void setOut( PrintStream out ) Der Standardausgabekanal wird umgesetzt. |
| void setErr( PrintStream err ) Der Fehlerkanal wird auf den PrintStream err gesetzt. |
| void setIn( InputStream in ) Der Eingabestrom kann umgesetzt werden, um beispielsweise aus einer Datei oder Netzwerkverbindung Daten zu beziehen, die an in anliegen sollen. |
Sehr erstaunlich in der System-Klasse ist, dass die Attribute in, out und err final sind und daher eigentlich nicht geändert werden können. Die Implementierung sieht deshalb auch etwas ungewöhnlich aus:
public final static InputStream in = nullInputStream(); public final static PrintStream out = nullPrintStream(); public final static PrintStream err = nullPrintStream();
Die Methode nullPrintStream() ist noch skurriler.
private static InputStream nullInputStream() throws NullPointerException { if (currentTimeMillis() > 0) return null; throw new NullPointerException(); }
Da bleibt natürlich die Frage, wieso die Sun-Entwickler nicht gleich den Wert auf null gesetzt haben. Denn nichts anderes macht ja die intelligente Funktion. Die Lösung liegt im final-Konstruktor und in einer Compiler-Optimierung. Da finale Variablen später (eigentlich) nicht mehr verändert werden dürfen, kann der Compiler überall dort, wo in, out oder err vorkommt, eine null einsetzen und nicht mehr auf die Variablen zurückgreifen. Dies muss aber verboten werden, da diese drei Attribute später mit sinnvollen Referenzen belegt werden. Genauer gesagt ist dafür die Methode initializeSystemClass() zuständig. Ursprünglich kommen die Ströme aus dem FileDescriptor.
Für err und out werden dann hübsche BufferedOutputStream mit 128 Bytes Puffer angelegt, die sofort durchschreiben. in ist ein einfacher BufferedInputStream mit der Standardpuffergröße. Damit setIn(), setOut() und setErr() dann auf die final-Variable schreiben dürfen, müssen selbstverständlich native Methoden her, die setIn0(in), setOut0(out) und setErr0(err) heißen. Die Parameter der Funktionen sind die Parameter der Set-Methoden. In initializeSystemClass() werden dann auch auf den gepufferten Strömen diese nativen Methoden angewendet.
Die Bastelei mit der nullPrintStream()-Methode ist nicht nötig, wenn der Java-Standard 1.1 vorliegt. Denn dort hat sich eine Kleinigkeit getan, die erst zu der umständlichen Lösung führte. Warum musste denn der Compiler die final-Variablen auch vorbelegen? Die Antwort ist, dass der 1.0-konforme Compiler direkt die final-Variablen initialisieren musste. Erst seit 1.1 kann an einer anderen Stelle genau einmal auf final-Variablen schreibend zugegriffen werden. Wir haben das schon an anderer Stelle beschrieben und die fehlerhafte Jikes-Implementierung aufgeführt, die auch zu Anfang in Javac zu Problemen bei der Doppelbelegung führte. Legen wir einen Java-1.1-Compiler zugrunde, was heute selbstverständlich ist, lässt sich die nullPrintStream() vermeiden. Wir können das an der Kaffe-Implementierung überprüfen, denn dort findet sich einfach:
final public static InputStream in; final public static PrintStream out; final public static PrintStream err;
Jetzt wird an einer definierten Stelle die Ein- beziehungsweise Ausgabe initialisiert.
in = new BufferedInputStream( new FileInputStream(FileDescriptor.in), 128); out = new PrintStream( new BufferedOutputStream( new FileOutputStream(FileDescriptor.out), 128), true); err = new PrintStream(new BufferedOutputStream( new FileOutputStream(FileDescriptor.err), 128), true);
Im Unterschied zur Sun-Implementierung muss hier nicht schon ein Aufruf der nativen Methoden verwendet werden, obwohl dies spätestens bei den setXXX()-Methoden nötig wird. Die Einfachheit einer solchen nativen Routine wollen wir uns zum Schluss einmal an setOut0() ansehen:
void Java_java_lang_System_setOut0 (JNIEnv *env, jclass system, jobject stream) { jfieldID out = (*env)->GetStaticFieldID( env, system, "out", "Ljava/io/PrintStream;"); assert(out); (*env)->SetStaticObjectField(env, system, out, stream); }
Dies zeigt noch einmal sehr deutlich, dass final durch native Methoden außer Kraft gesetzt werden kann. Diese Lösung ist aber, wie wir schon festgestellt haben, sehr unschön. Damit aber die einfache Verwendung von out, err und in als Attribut möglich ist, bleibt außer dieser Konstruktion nicht viel übrig. Andernfalls hätte eine Methode Eingang finden müssen, aber
System.out().println( "Hui Buh" );
macht sich nicht so schön. Ließen sich in Java Variablen mit einem speziellen Modifizierer versehen, der nur den Lesezugriff von außen gewährt und nicht automatisch einen Schreibzugriff, so wäre das auch eine Lösung. Doch so etwas gibt es in Java nicht. Softwaredesigner würden sowieso Methoden nehmen, da sie Variablenzugriffe meist meiden.
Bei genauerer Betrachtung der Standardausgabe- und Eingabemethoden ist festzustellen, dass das Konzept nicht besonders plattformunabhängig ist. Wenn wir einen Macintosh als Plattform betrachten, dann lässt sich dort keine Konsole ausmachen. Bei GUI-Anwendungen spricht demnach einiges dafür, auf die Konsolenausgabe zu verzichten und die Ausgabe in ein Fenster zu setzen. Ich möchte daher an dieser Stelle etwas vorgreifen und ein Programmstück vorstellen, mit dem sich die Standardausgabeströme in einem Fenster darstellen lassen. Dann genügt Folgendes, unter der Annahme, dass die Variable ta ein TextArea-Objekt referenziert:
PrintStream p = new PrintStream( new OutputStream() { public void write( int b ) { ta.append ( (char)b ); } } ); System.setErr( p ); System.setOut( p );
Die Java-Umgebung setzt keine spezielle grafische Architektur voraus und kein spezielles Terminal. Als unabhängige Sprache gibt es daher außer der Textausgabe bisher keine Möglichkeit, die Farben für die Textzeichen zu ändern, den Cursor zu setzen oder den Bildschirm zu löschen. Bei Programmen mit Textausgabe sind dies aber gewünschte Eigenschaften. Wir können jedoch bei speziellen Terminals Kontrollzeichen ausgeben, so dass die Konsole Attribute speichert und Text somit formatiert ausgegeben werden kann. Bei einem VT100-Terminal existieren unterschiedliche Kontrollsequenzen, und über eine einfache Ausgabe System.out.println() lässt sich der Bildschirm löschen.
System.out.println( "\u001b[H\u001b[2J" );
Leider ist diese Lösung nur lauffähig auf einem VT100-Terminal. Andere Varianten müssen speziell angepasst werden.
Die Bibliothek Jcurzez ist die Java-Version der Curses-Bibliothek, die Ausgaben auf einem Terminal steuert. Mit Jcurzez lassen sich Zeichenattribute auf der Konsole ändern, lässt den Cursor wandern und lassen sich einfache ASCII-Fenster erstellen. Die Bibliothek ist unter http://www.freesoftware.fsf.org/jcurzez/ zu bekommen.
Natürlich ist es Schreibarbeit, immer die Angabe System.out.bla machen zu müssen, so wie in
System.out.println( "Das Programm gibt die Ausgabe: " ); System.out.println( 1.234 ); System.out.println( "Die drei Fragezeichen sind toll." );
Durch einen zusätzlichen Verweis können wir uns Arbeit sparen. Das Ganze funktioniert, da System.out ein Objekt vom Typ PrintStream ist.
Listing 12.12 SchnellerPrintStream.java
import java.io.*; public class SchnellerPrintStream { private static final PrintStream o = System.out; public static void main( String args[] ) { o.println( "Neu!" ); o.println( "Jetzt noch weniger zu schreiben." ); o.println( "Hilft auch Gelenken wieder auf die Sprünge!" ); } }
In der Klasse OutputStream taucht die Funktion println() nicht auf. Für Systemausgaben wäre OutputStream auch viel zu unflexibel, daher nutzt die Klasse auch PrintStream-Objekte ab. Für eigene Projekte sollte die Klasse nicht mehr verwendet werden und wenn doch, dann nur noch für Debug-Code mittels System.out und aus Kompatibilitätsgründen. Wir stützen uns daher auf die Klasse PrintWriter, die die abstrakte Klasse Writer erweitert. Das Attribut System.out bleibt weiterhin vom Typ PrintStream. Die Deklaration PrintWriter o = System.out ist also falsch (das ist zum Beispiel solch ein Kompatibilitätsgrund).
Die Klasse ByteArrayOutputStream lässt sich gut verwenden, wenn mehrere unterschiedliche primitive Datentypen in ein Bytefeld kopiert werden sollen, die dann später eventuell binär weiterkodiert werden müssen. Erstellen wir etwa eine GIF-Datei1, so müssen wir nacheinander verschiedene Angaben schreiben. So erstellen wir leicht eine Grafikdatei im Speicher. Anschließend konvertieren wir mit toByteArray() den Inhalt des Datenstroms in ein Bytefeld.
ByteArrayOutputStream boas = new ByteArrayOutputStream(); DataOutputStream out = new DataOutputStream( boas ); // Header out.write( 'G' ); out.write( 'I' ); out.write( 'F' ); out.write( '8' ); out.write( '9' ); out.write( 'a' ); // Logical Screen Descriptor out.writeShort( 128 ); // Logical Screen Width (Unsigned) out.writeShort( 37 ); // Logical Screen Height (Unsigned) // <Packed Fields>, Background Color Index, Pixel Aspect Ratio // und so weiter. out.close(); byte result[] = out.toByteArray();
Ein SequenceInputStream-Filter hängt mehrere Eingabeströme zu einem großen Eingabestrom zusammen. Nützlich ist dies, wenn wir aus Strömen lesen wollen und es uns egal ist, was für ein Strom es ist, wo er startet und wo er aufhört.
Ein SequenceInputStream lässt sich erzeugen, indem im Konstruktor zwei InputStream-Objekte mitgegeben werden. Soll aus zwei Dateien ein zusammengesetzter Datenstrom gebildet werden, nutzen wir folgende Programmzeilen:
InputStream s1 = new FileInputStream( "teil1.txt" ); InputStream s2 = new FileInputStream( "teil2.txt" ); InputStream s = new SequenceInputStream( s1, s2 );
Ein Aufruf irgendeiner read()-Methode liest nun erst Daten aus s1. Liefert s1 keine Daten mehr, kommen die Daten aus s2. Liegen keine Daten mehr an s2, aber wieder an s1, ist es zu spät. Natürlich hätten wir diese Funktionalität auch selbst programmieren können, doch wenn etwa eine Methode nur einen InputStream verlangt, ist diese Klasse sehr hilfreich.
Für drei Ströme kann eine Kette aus zwei SequenceInputStream-Objekten gebaut werden.
InputStream in = new SequenceInputStream( stream1, new SequenceInputStream(stream2, stream3) );
Sollen mehr als zwei Ströme miteinander verbunden werden, kann auch eine Enumeration im Konstruktor übergeben werden. Die Enumeration einer Datenstruktur gibt dann die zu kombinierenden Datenströme zurück. Wir haben eine Datenstruktur, die sich hier gut anbietet: Vector. Wir packen alle Eingabeströme in einen Vector und nutzen dann die elements()-Methode für die Aufzählung.
Vector v = new Vector(); v.addElement( stream1 ); v.addElement( stream2 ); v.addElement( stream3 ); InputStream seq = new SequenceInputStream( v.elements() );
class java.io.SequenceInputStream extends InputStream |
| SequenceInputStream( InputStream s1, InputStream s2 ) Erzeugt einen SequenceInputStream aus zwei einzelnen InputStream-Objekten. Zuerst werden die Daten aus s1 gelesen und dann aus s2. |
| SequenceInputStream( Enumeration e ) Die Eingabeströme für den SequenceInputStream werden aus der Enumeration mit next Element() geholt. Ist ein Strom ausgesaugt, wird die close()-Methode aufgerufen und der nächste vorhandene Strom geöffnet. |
| int available() throws IOException Liefert die Anzahl der Zeichen, die gelesen werden können. Die Daten betreffen immer den aktuellen Strom. |
| int read() throws IOException Liefert das Zeichen oder -1, wenn das Ende aller Datenströme erreicht ist. |
| int read( byte b[], int off, int len ) throws IOException Liest Zeichen in ein Feld und gibt die Anzahl tatsächlich gelesener Zeichen oder -1 zurück. |
| void close() throws IOException Schließt alle Ströme, die vom SequenceInputStream-Objekt eingebunden sind. |
Das nachfolgende Programm zeigt, wie ein StringBufferInputStream mit einem Datenstrom zusammengelegt wird. Es werden anschließend Zeilennummern und Zeileninhalt ausgeben, wobei sehr schön deutlich wird, dass erst der String und dann die Datei ausgelesen wird. Die Datei muss sich im Pfad befinden, da sie sonst nicht gefunden werden kann.
Listing 12.13 SequenceInputStreamDemo.java
import java.io.*; public class SequenceInputStreamDemo { public static void main( String args[] ) { String s = "Gezeitenrechnung\nfür\nSchlickrutscher\n"; StringBufferInputStream sbis = new StringBufferInputStream( s ); InputStream fis = SequenceInputStreamDemo.class.getResourceAsStream( "cat.java" ); SequenceInputStream sis = new SequenceInputStream( sbis, fis ); LineNumberInputStream lsis = new LineNumberInputStream( sis ); System.out.print( "0: " ); try { for ( int c; (c = lsis.read()) != -1; ) System.out.print( (c == '\n') ? ("\n" + lsis.getLineNumber() + ": ") : ""+(char)c ); } catch ( IOException e ) { System.out.println( e ); } System.out.println(); } }
Leider verwendet das Programm zwei veraltete Klassen: StringBufferInputStream und LineNumberInputStream. Wir sind angehalten, für beide Ströme Reader-Klassen zu nutzen. Doch da es nur für Streams, aber nicht für Reader, einen Sequence-Strom gibt (eine Klasse SequenceReader haben die Entwickler wohl in ihrer Aufregung vergessen), haben die beiden veralteten Klassen zur Demonstration ihre Berechtigung. Die ersten Zeilen der Ausgabe sind:
0: Gezeitenrechnung 1: für 2: Schlickrutscher 3: import java.io.*; 4: 5: class cat 6: { 7: public static void main( String args[] ) 8: { 9: for ( int i=0; i < args.length; i++ ) 10: { ...
1 Mehr zu Grafikformaten unter>http://www.oreilly.com/centers/gff/gff-faq/gff-faq3.htm.
| << zurück |
Copyright (c) Galileo Press GmbH 2004
Für Ihren privaten Gebrauch dürfen Sie die Online-Version natürlich ausdrucken. Ansonsten unterliegt das <openbook> denselben Bestimmungen, wie die gebundene Ausgabe: Das Werk einschließlich aller seiner Teile ist urheberrechtlich geschützt. Alle Rechte vorbehalten einschließlich der Vervielfältigung, Übersetzung, Mikroverfilmung sowie Einspeicherung und Verarbeitung in elektronischen Systemen.
