Kapitel 18 Verteilte Programmierung mit RMI und SOAP
Ich denke, dass es einen Weltmarkt für vielleicht fünf Computer gibt.
- Thomas Watson, Vorsitzender von IBM, 1943
18.1 Entfernte Methoden 
Bei Funktionsaufrufen nutzen wir die Intelligenz der Methode, die zu gegebenen Eingabeparametern Ausgangswerte liefert oder einen Systemzustand verändert. Die Methode ist in diesem Fall Anbieter einer ganz speziellen Dienstleistung. Wenn wir zu einer Eingabeanfrage eine Antwort bekommen wollen, die Implementierung dieser Intelligenz aber auf einer anderen Maschine liegt, so bleibt die Frage nach einer eleganten Implementierung. Der klassische Weg führt über Client-Server-Systeme. Der Client formuliert eine Anfrage, die vom Server verstanden und interpretiert wird. So sieht dies etwa in einfacher Form mit einem Datenbank-Server aus. Der Client möchte zum Beispiel den Umsatz an Comics herausfinden. Er schickt dann eine Anfrage, und das Ergebnis wird zurückgeschickt und ausgewertet. Diese Kommunikation zwischen verteilten Prozessen muss aber aufwändig bei Client-Server-Systemen implementiert werden. Wünschenswert ist eine Sicht auf entfernte Dienste wie auf Methoden eines Einprozessorsystems. Ideal wäre es, wenn ein Funktionsaufruf auf einen Server so aussähe, als ob es eine lokale Funktion wäre.
 18.1.1 Wie entfernte Methoden arbeiten
Glücklicherweise haben Birrel und Nelson schon 1984 ein Modell vorgestellt, das entfernte Server-Funktionen wie lokale Funktionen aussehen lässt. Die grundlegende Idee dabei ist, eine Stellvertreterfunktion anzubieten, die den tatsächlichen Übertragungsvorgang verdeckt. Wir wollen uns dies an einem Beispiel klarmachen. Nehmen wir an, der Client möchte die Funktion String crackPasswort(String) nutzen, die in Wirklichkeit auf einem ganz anderen Rechner angeboten wird: auf einem, der richtig Power hat. Da wir aber die Vorgabe haben, eine entfernte Funktion so aussehen zu lassen wie eine lokale, wird nun crackPasswort() wie gewohnt aufgerufen.
System.out.println( crackPasswort( "v4ghd,sjh324" ) );
Auf dem Server muss nun die Implementierung von crackPasswort() zu finden sein.
String crackPasswort()
{
// Etwa durch Tabellen und vielen Schleifen brute-force Attacke.
}
18.1.2 Stellvertreter (Proxy)
Jetzt fehlt nur noch die Verbindung von Client und Server. Dies wird durch die so genannten Stellvertreterobjekte (engl. proxies) realisiert. Diese existieren auf der Client- und auf der Server-Seite. Der Client spricht demnach nicht mit dem Server, sondern mit einer Funktion, die so aussieht wie eine Server-Funktion. In Wirklichkeit nimmt sie die Parameter, verpackt sie in eine Server-Anfrage und schickt sie weg. So finden wir auf der Client-Seite etwa Folgendes:
String crackPasswort( String passwort )
{
// Verbindung aufbauen (etwa über Sockets)
// Das Passwort nehmen und zum Server schicken (write()).
// Auf das Ergebnis vom Server warten
// return ergebnis;
}
Und dies ist das klassische Client-Server-Konzept, welches wir schon von Sockets her kennen. Der Client mit dem Funktionsaufruf initiiert die Anfrage, und der Server wartet, bis ein williger Kunde eintrifft. Der Server nimmt die Anfragen vom Client entgegen, entnimmt aus dem Anforderungspaket die Daten und ruft die lokale Funktion auf. Dazu kann auch auf der Server-Seite ein Stellvertreter existieren. Es reicht aber auch ein Server aus, der zunächst auf eingehende Anfragen wartet und dann die entsprechenden Funktionen ohne einen eigenen Stellvertreter aufruft.
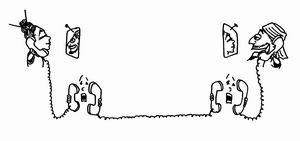
Hier klicken, um das Bild zu Vergrößern
Der Client merkt also nicht, dass der Stellvertreter die Daten weiterleitet, und der Server merkt nicht, dass er in Wirklichkeit nicht mit lokalen Daten gefüttert wird. Natürlich wäre es müßig, diese Stellvertreter selbst zu programmieren. Dies macht glücklicherweise ein Hilfsprogramm.
18.1.3 RMI
RMI (Remote Method Invocation) ist der Mechanismus in Java, um entfernte Objekte und deren Angebote zu nutzen. Auch schon der Vorgänger in der prozeduralen Welt, RPC (Remote Procedure Call), ist eine Entwicklung von Sun. Mit RMI lässt sich somit auf hohem Abstraktionsniveau arbeiten. Stellvertreter nehmen die Daten entgegen und übertragen sie zum Server. Nach der Antwort präsentiert der Stellvertreter das Ergebnis.
18.1.4 Wie die Stellvertreter die Daten übertragen
Für RMI gibt es wie bei TCP/IP ein Schichtenmodell, das aus mehreren Ebenen besteht. Die oberste Ebene mit dem höchsten Abstraktionsgrad nutzt einfach einen Transportdienst der darunter liegenden Ebene. Dessen Aufgabe ist es, die Daten wirklich zu übermitteln, und die Stellvertreter realisieren es, die Parameter irgendwie von einem Ort zum anderen zu bewegen. Sie setzen also die Transportschicht um.
Eine Implementierung über Sockets
Wir können uns vorstellen, dass die Stellvertreter eine Socket-Verbindung nutzen. Der Server horcht dann in accept() auf einkommende Anfragen, und der Stellvertreter vom Client baut anschließend die Verbindung auf. Sind die Parameter der Funktion primitive Werte, dann können sie in unterschiedliche write()- und read()-Methoden umgesetzt werden. Doch auch bei komplexen Objekten wie Listen hat Java keine Probleme, da es ja eine Serialisierung gibt. Objekte werden dann einfach plattgeklopft, übertragen und auf der anderen Seite wieder ausgepackt. Bei entfernten Methodenaufrufen wird neben der Serialisierung auch der Begriff Marshalling verwendet. Somit ist das Verhalten wie bei lokalen Methoden fast abgebildet, insbesondere der synchrone Charakter. Die lokale Funktion blockiert so lange, bis das Ergebnis der entfernten Methoden ankommt.
RMI Transport Protocol
Die Übertragung mittels Sockets ist nur eine Möglichkeit. Neben den Sockets implementiert Java-RMI für Firewalls auch die Übermittlung über HTTP-Anfragen. Wir werden in einem späteren Kapitel darauf zurückkommen. Zusammen nennen sich die Protokolle RMI Wire Protocol. Bei Sockets wird hier TCP genutzt. Über eine eigene RMI-Transportschicht könnten auch andere Protokolle genutzt werden, etwa über UPD oder gesicherte Verbindungen mit SSL. Verschlüsselte RMI-Verbindungen über SSL sind nicht schwer, wie es ein Beispiel von Sun unter http://java.sun.com/j2se/1.4.1/docs/guide/security/jsse/samples/index.html zeigt.
18.1.5 Probleme mit entfernten Methoden
Das Konzept scheint entfernte Methoden abzubilden wie lokale. Doch es gibt einige feine Unterschiede, so dass wir nicht damit anfangen müssen, alle lokale Methoden zu verteilen, weil gerade mal ein entfernter Rechner schön schnell ist.
 |
Zunächst einmal müssen wir ein Kommunikationssystem voraussetzen. Damit fangen aber die unter Client beziehungsweise Server bekannten Probleme an. Was passiert, wenn das Kommunikationssystem zusammenbricht? Was passiert mit verstümmelten Daten? |
|
Da beide Rechner eigene Lebenszyklen haben, ist nicht immer klar, dass beide Partner miteinander kommunizieren können. Wenn der Server nicht ansprechbar ist, muss der Client darauf reagieren. Hier bleibt nichts anderes übrig, als über einen Zeitablauf (Timeout) zu gehen. |
|
Da Client und Server über das Kommunikationssystem miteinander sprechen, ist die Zeit für die Abarbeitung eines Auftrags um ein Vielfaches höher als bei lokalen Methodenaufrufen. Zu den Kommunikationskosten über das Rechennetzwerk kommen die Kosten für die zeitaufwändige Serialisierung hinzu, die besonders in den ersten Versionen des JDKs hoch waren. |
Parameterübergabe bei getrenntem Speicher
Doch der wirkliche Unterschied zwischen lokalen und entfernten Methoden ist das Fehlen des gemeinsamen Kontexts. Die involvierten Rechner führen ihr eigenes Leben mit ihren eigenen Speicherbereichen. Stehen auf einer Maschine zum Beispiel statische Variablen jedem zur Verfügung, so ist dies bei entfernten Maschinen nicht der Fall. Ebenso gilt dies für Objekte, die von mehreren Partnern geteilt werden. Die Daten auf einer Maschine müssen erst übertragen werden, also arbeitet der Server mit einer Kopie der Daten. Bei primitiven Daten ist das kein Thema, schwierig wird es erst bei Objektreferenzen. Mit der Referenz auf ein Objekt kann der andere Partner nichts anfangen. Aber mit der Übertragung der Objekte fangen wir uns zwei weitere Probleme ein.
|
Erstens muss der Zugriff exklusiv erfolgen, da andere Teilnehmer den Objektzustand ja unter Umständen ändern können. Wenn wir also eine Referenz übergeben und das Objekt wird serialisiert, könnte der lokale Teilnehmer Änderungen vornehmen, die beim Zurückspielen vom Server eventuell verloren gehen könnten. |
|
Damit haben wir zweitens den Nachteil, dass nicht einfach eine Referenz reicht. Große Objekte müssen immer wieder vollständig serialisiert werden. Und mit dem Mechanismus des Serialisierens fangen wir uns ein Problem ein: Nicht alle Objekte sind per se serialisierbar. Gerade die Systemklassen lassen sich nicht so einfach übertragen. Bei einer Trennung von Datenbank und Applikation wird das deutlich. Eine hübsche Lösung wäre etwa, ein RMI-Programm für die Datenbankanbindung einzusetzen und eine Applikation, die mit dem RMI-Programm spricht, um unabhängig von der Datenbank zu sein. (RMI nimmt hier die Stelle als so genannte Middleware ein.) Bedauerlicherweise implementiert keine der Klassen im Paket java.sql die Schnittstelle Serializable. Die Ergebnisse müssen in einem neuen Objekt verpackt und verschickt werden. |
Wenn die Daten übertragen werden, müssen sich die Partner zudem über das Austauschformat geeinigt haben. Die Daten müssen von beiden verstanden werden. Traditionell bieten sich zwei Verfahren an.
|
Zunächst ein symmetrisches Verfahren. Alle Parameter werden in einem festen Format übertragen. Auch wenn Client und Server die Daten gleich darstellen, werden sie in ein neutrales Übertragungsformat konvertiert. |
|
Dem gegenüber steht das asymmetrische Verfahren. Hier schickt jeder Client die Daten in einem eigenem Format, und der Server hat verschiedene Konvertierungsfunktionen, um die Daten zu erkennen. |
|
Da wir uns innerhalb von Java und den Konventionen bewegen, müssen wir uns über das Datenformat keine Gedanken machen. Java konvertiert die Daten unterschiedlichster Plattformen immer gleich. Daher handelt es sich um ein symmetrisches Übertragungsprotokoll. |
|


