|
|
|
|||||
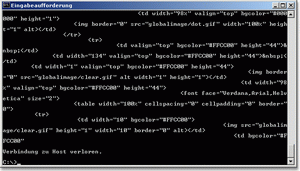
Eine Beispielanfrage an einen Web-ServerHier ein typisches Beispiel einer GET-Anfrage vom Client an den Standard-Web-Server: GET /directory/index.html HTTP/1.1 Das erste Wort ist die Methode des Aufrufs (auch Anfrage, engl. request). Neben den drei oben aufgeführten Methoden GET, POST und HEAD gibt es noch weitere, meist finden diese aber nur bei speziellen Anwendungen Verwendung.
Tabelle 16.3 Einige Anfragemethoden von HTTP Der zweite Parameter bei der Anfrage an den Server ist der Dateipfad. Er ist als relative Pfadangabe zu sehen und er folgt hinter der Methode.
Die Anfrage endet nur bei einer Leerzeile (Zeile, die nur ein Carriage-Return (\r) und ein Linefeed (\n) enthält).
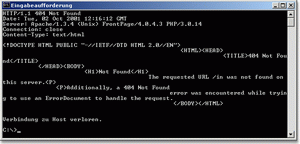
Abbildung 16.1 Get-Anfrage über telnet an einen Web-Server Wenn die GET-Anfrage falsch formuliert oder die Datei nicht vorhanden ist, folgt eine Fehlerausgabe (siehe Abbildung 16.2).
Abbildung 16.2 Ungültige Datei Nach der Zeile mit der Anfrage können optionale Zeilen gesendet werden. So stellt der Netscape Navigator 2.0 (also der Client) beispielsweise die folgende Anfrage an den Server: GET / HTTP/1.0 Connection: Keep-Alive User-Agent: Mozilla/2.0 (Win95; I) Host: merlin Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */* Hier sehen wir, dass durch diese Plauderei leicht Statistiken vom Browsereinsatz gemacht werden können.  16.13.3 Die Antworten vom Server
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1xx: Informierend Die Anfrage ist angekommen, und alles geht weiter. |
| 2xx: Erfolgreich Die Aktion wurde erfolgreich empfangen, verstanden und akzeptiert. |
| 3xx: Rückfrage Um die Anfrage auszuführen, sind noch weitere Angaben nötig. |
| 4xx: Fehler beim Client Die Anfrage ist syntaktisch falsch oder kann nicht ausgeführt werden. |
| 5xx: Fehler beim Server Der Server kann die wahrscheinlich korrekte Anfrage nicht ausführen. |
Gehen wir noch etwas genauer auf die Fehlertypen ein.
| Statuscode | Optionaler Text |
|---|---|
| 200 | OK |
| 201 | Created |
| 202 | Accepted |
| 204 | No Content |
| 300 | Multiple Choices |
| 301 | Moved Permanently |
| 302 | Moved Temporarily |
| 304 | Not Modified |
| 400 | Bad Request |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not Found |
| 500 | Internal Server Error |
| 501 | Not Implemented |
| 502 | Bad Gateway |
| 503 | Service Unavailable |
Tabelle 16.4 Einige Statuscodes bei Antworten des HTTP-Servers
Am häufigsten handelt es sich bei den Rückgabewerten um
| 200 OK Die Anfrage vom Client war korrekt, und die Antwort vom Server stellt die gewünschte Information bereit. |
| 404 Not Found Das referenzierte Dokument kann nicht gefunden werden. |
| 500 Internal Server Error Meistens durch schlechte CGI-Programme hervorgerufen. |
Der Text in der Tabelle kann vom Statuscode abweichen.
Zu jeder übermittelten Nachricht (nicht Entity) gibt es abfragbare Felder. Diese gelten sowohl für den Client als auch für den Server. Zu diesen gehören: Cache-Control, Connection, Date, Pragma, Transfer-Encoding, Upgrade und Via. Zu den Header-Informationen gehört auch die Uhrzeit des abgesendeten Pakets. Das Datum kann in drei verschiedenen Formaten gesendet werden, wobei das erste zum Internet-Standard gehört und dementsprechend wünschenswert ist. Es hat gegenüber dem zweiten den Vorteil, dass es eine feste Läge besitzt und das Jahr mit vier Ziffern darstellt:
Sun, 06 Nov 1994 08:49:37 GMT ; RFC 822, update in RFC 1123 Sunday, 06-Nov-94 08:49:37 GMT ; RFC 850, obsolet seit RFC 1036 Sun Nov 6 08:49:37 1994 ; ANSI C asctime() Format
Ein HTTP/1.1-Client, der die Datumswerte ausliest, muss also drei Datumsformate akzeptieren.
Der Response-Header erlaubt dem Server, zusätzliche Informationen, die nicht in der Statuszeile kodiert sind, zu übermitteln. Die Felder geben Auskunft über den Server. Folgende Felder sind möglich: Age, Location, Proxy-Authenticate, Public, Retry-After, Server, Vary, Warning und WWW-Authenticate.
Eine Entity ist eine Information, die aufgrund einer Anfrage gesendet wird. Die Entity besteht aus einer Metainformation (Entity-Header) und der Nachricht selbst (überliefert im Entity-Body). Die Metainformationen, die in einem der Entity-Header-Felder übermittelt werden, sind etwa Informationen über die Länge des Blocks oder über die letzte Änderung der Länge. Ist kein Entity-Body definiert, so liefern die Felder Informationen über die Ressourcen, ohne sie wirklich im Entity-Body zu senden: Allow, Content-Base, Content-Encoding, Content-Language, Content-Length, Content-Location, Content-MD5, Content-Range, Content-Type, ETag, Expires und Last-Modified.
HTTP nutzt die Internet Media-Types (verwandt mit MIME-Types) im Content-Type. Dieser Content-Type gibt den Datentyp des übermittelten Datenstroms an. Einige Beispiele mit Referenzen:
| Type | Untertyp | Beschreibung |
|---|---|---|
| text | plain | ASCII-Text (RFC1521) |
| html | Hyper-Text Markup Language (RFC1866) | |
| multipart | mixed | Mehrere Inhalte (RFC1521) |
| form-data | Formulardaten aus HTML (RFC1867) | |
| application | octet-stream | Allgemeine Binärdaten (RFC1521) |
| postscript | Postscript von Adobe (RFC1521) | |
| rtf | Rich Text Format | |
| PDF von Adobe | ||
| vnd.ms-excel | Microsoft Excel | |
| vnd.ms-powerpoint | Microsoft Powerpoint |
Jede über HTTP/1.1 übermittelte Nachricht mit einem Entity-Body sollte einen Header mit Content-Type enthalten. Ist dieser Typ nicht gegeben, so versucht der Client anhand der Endung der URL oder durch Betrachtung des Datenstroms herauszufinden, um was für einen Typ es sich handelt. Bleibt dies jedoch unklar, wird ihm der Typ »application/octet-stream« zugewiesen. Content-Types werden gerne benutzt, um Daten zu komprimieren. Diese verlieren dadurch nicht ihre Identität. In diesem Fall ist das Feld Content-Encoding im Entity-Header gesetzt, und bei einem GNU Zip-Packverfahren1 (gzip) ist dann folgende Zeile im Datenstrom mit dabei:
Content-Encoding: gzip
Nach den Headern folgt als Antwort die Datei. Nachdem diese übertragen wurde, wird die Socket-Verbindung geschlossen. Da jedes Anfrage/Antwort-Paar in einer Socket-Verbindung mündet, ist dieses Verfahren nicht besonders schnell und schont auch nicht das Netzwerk, da viele Pakete verschickt werden müssen, die sich um den Aufbau der Leitung kümmern.
1 Eine Lempel-Ziv-Kodierung (LZ77) mit einem 32 -Bit-CRC. Beschrieben in RFC 1952.
| << zurück |
Copyright (c) Galileo Press GmbH 2004
Für Ihren privaten Gebrauch dürfen Sie die Online-Version natürlich ausdrucken. Ansonsten unterliegt das <openbook> denselben Bestimmungen, wie die gebundene Ausgabe: Das Werk einschließlich aller seiner Teile ist urheberrechtlich geschützt. Alle Rechte vorbehalten einschließlich der Vervielfältigung, Übersetzung, Mikroverfilmung sowie Einspeicherung und Verarbeitung in elektronischen Systemen.